根据 Sepp,期权的价值由以下的四部分组成:
1. 复制成本(已实现𝐺𝑎𝑚𝑚𝑎) = 已实现波动率 × 𝐺𝑎𝑚𝑚𝑎
2. 交易成本(𝑑𝑒𝑙𝑡𝑎对冲) = |已实现𝐺𝑎𝑚𝑚𝑎| × 买卖差价
3. 敞口风险(无法对冲的𝑑𝑒𝑙𝑡𝑎风险) = 价格崩溃或低流动性
4. 市场估值(𝑣𝑒𝑔𝑎)风险 = 隐含波动率的变化
我们可以使用实际波动率来预测波动率的风险溢价。我们可以通过买入点差较小的期权和卖出点差较大的期权来进行 Delta 对冲。我们也可以通过实际波动率来预测期权价格的回撤。
期权策略盈亏
本文中,通过 Delta 对冲的跨式期权的收益由以下公式表达:
收益 = 时间衰减(𝑇ℎ𝑒𝑡𝑎 盈亏) - 实际凸性( 𝐺𝑎𝑚𝑚𝑎盈亏)

在监督性学习过程中,作者使用了多类别的波动率模型。
1. 样本空间估计量:这是一种日内估计量。它假设波动率满足随机游走性质。
2. GARCH 模型
3. 贝叶斯参数模型
4. 隐马尔科夫模型
我们如何判断模型是否存在过拟合的情况?作者否定了根据策略盈亏来判断模型表现的方法并给出了三个原因。第一, Delta 对冲策略存在很强的周期性。某一阶段的亏损并不能代表模型一定存在过拟合的情况。第二,与线性的买卖预测不同,波动率预测本身会影响对冲的决策。第三,与正股不同,期权策略被许多不同因素共同影响着:行权价格、行权日期、对冲策略等。
如果盈亏不是很好的评价方式,我们应如何评价波动率模型的表现?作者给出的答案是将模型的预测与基准测试的结果进行比较。例如,对于日终对冲,我们可以将模型预测的收盘波动率与基准进行比较。我们同时也可以通过分布测试来判断预测结果的稳定性。
定义模型的样本分布𝑍(𝑛):
𝑍(𝑛) =现回报(𝑛)/动率预测(𝑛)
对于一个强有力的模型, 𝑍(𝑛)应该遵循标准正态分布。我们可以通过正态检测来选出符合标准的模型。同时,一个强有力模型给出的波动率范围会是相对小且精确的。
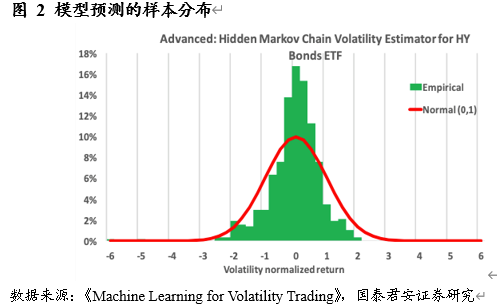
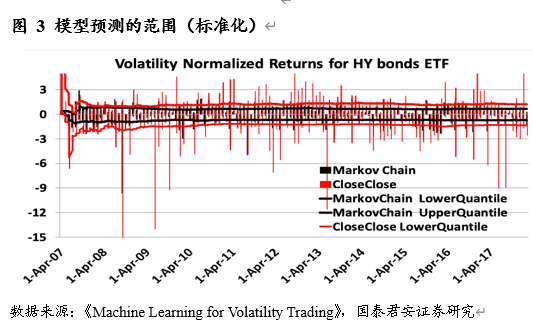
作者详细给出了一个完整通过监督性学习产生最佳模型的流程:
1. 选择备选模型:从( 3)中提到的四种类别中选出大于三十个具有不同参数的备选模型。
2. 统计测试:通过使用至少一种统计检验检测备选模型预测
3. 结果的统计功效。
4. 备选模型的排名:我们可以对备选模型通过不同的统计监测进行排序。对于 M 种统计测试,我们可以得到 M 种不同的排名
5. 根据排名选择模型:在这一步,选择排名靠前的模型或模型组合
6. 监督性学习:以上的步骤将会周期化(交易日/月/年)执行。在通过分析一定量的排名与选择结果后,我们可以在下一次的排名时利用这些历史数据去预测排名靠前的组合。
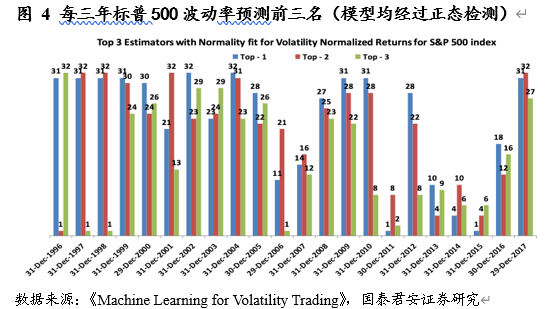
例子1 标普 500 指数波动率
在这个例子里,作者使用了三年的滑动窗口对不同模型的表现进行了预测。作者将备选模型进行了编号( 1, 2, 3,……)。在预测标普 500 指数波动率上,马尔可夫模型 31 和 32 常常取得榜首。同时,作为相对简单的模型,日内模型 1-10 也十分可靠。
例子2 财报日对预测的影响
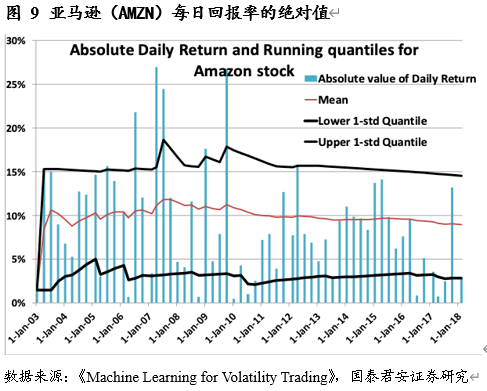
在财报日,股票的涨跌及有关期权的日内波动率常常会有非常极端的变化。
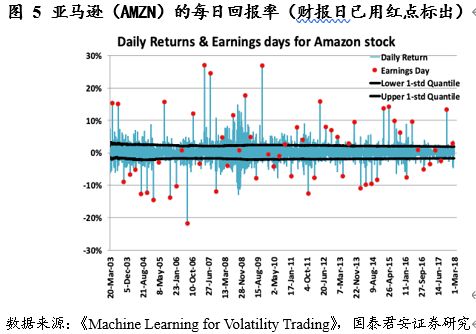
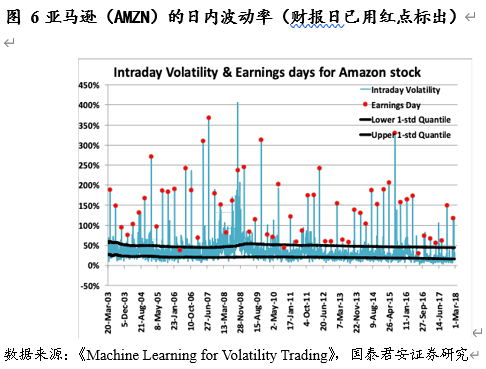
具体地说,我们可以通过给予财报日日期相对高的权重(隐含与实际波动率)来解决这个问题。我们可以通过分析平值期权的周期性结构特征来得到隐含波动率的调整参数。对于实际波动率,分析历史数据是给出权重的一个重要的方法。
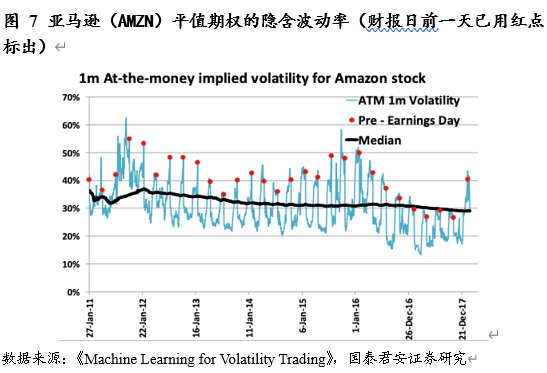
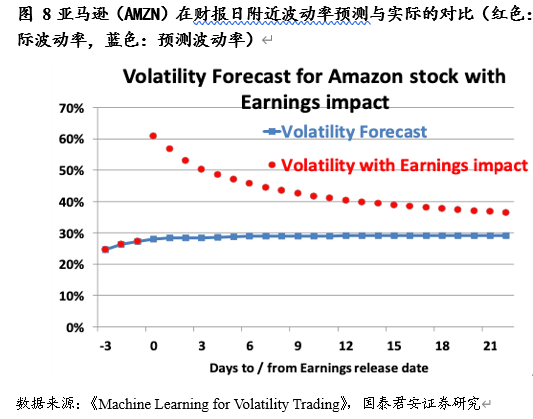
在获得隐含波动率之后,财报当天回报率的绝对值即可通过以下公式得出:
|期望回报率| = 比例因子 × 预计日内波动率
我们可以通过对历史波动率与回报率进行线性回归来得到这个比例因子。
不同类资产通常具有不同的波动率。所以,对于不同类别的资产,我们需要对它们分别进行以上所提到的排序与选择流程。所以,实际的波动率预测将会有三个部分:
1. 将不同类别的资产(股指、科技股、期货、外汇市场等)数据进行分类。
2. 将以上提到的 N 种波动率模型分别应用于每一种资产上。之后,在每一种资产类别内通过 M 种统计测试分别对这 N 种模型进行排序。
3. 若我们需要预测某个标的的波动率,我们可以通过使用该资产所在类别中排名相对靠前的模型(或模型的组合)进行预测。
以上提到的监督性学习算法可以被类比为一种搜索引擎。如果我们想要执行标普 500 指数的 Delta 对冲策略,我们可以在 2018 年 5 月 14 日想要预测标普 500 指数下月的波动率(提出问询)。收到问询以后,“搜索引擎”(模型)将会依照以上提到的测试与排序结果输出最佳模型(或模型的线性组合)的波动率预测。最后,为保持高的“用户满意度”,我们可以根据实现盈亏来调整“搜索引擎”的权重,从而使下一次的波动率预测更为准确。 对于期权策略,本模型可以控制三种不同的期权风险
1. Delta 风险:标的资产价格的变化驱动了 Delta 值的变化。通过对不同类别标的给予不同的换算系数后将 Delta 的变化趋势进行聚合,本模型可以通过学习聚合数据来解决这个问题。
2. Vega 风险:Vega 风险主要来自于隐含波动率的剧烈变化与Delta 变化的双重影响。本模型可以通过学习不同行权日期/价格期权的 Vega 与 Delta 的聚合数据来解决这一问题。
3. Gamma 风险:Gamma 反映了期权对应标的价格变化的二阶导数( Delta 变化率)。为了防止对应标的变化的速度急速加快或减缓( Gamma 风险),特定情境下的压力测试是非常有必要的。
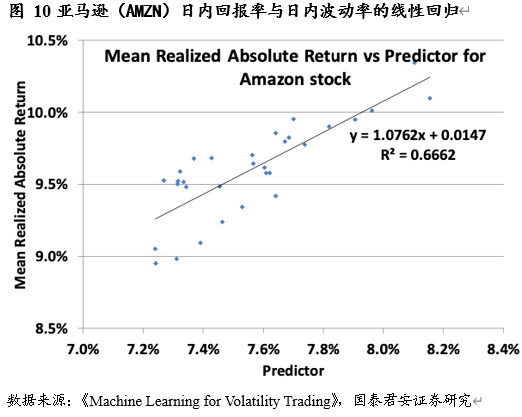
对于 Delta 与 Vega 风险而言,我们只有两到三个风险因子来预测它们的发生。为了解决该问题,我们需要对波动率曲面进行主成分分析。
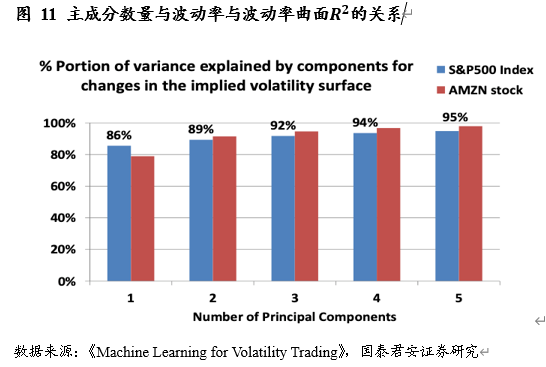
线性回归
线性回归对于减少 Delta 与 vega 风险都很有效。对于 Delta 风险而言,我们可以通过回归分析发现波动率与对应标的价格的关系。
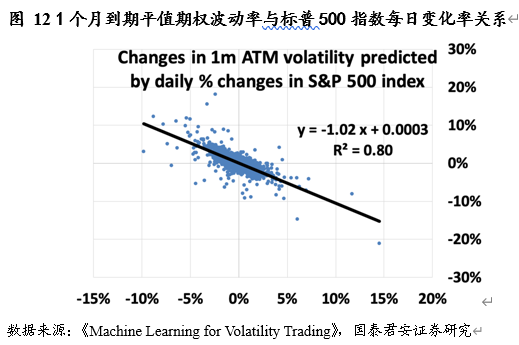
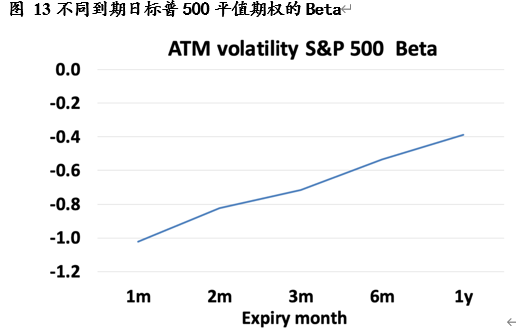
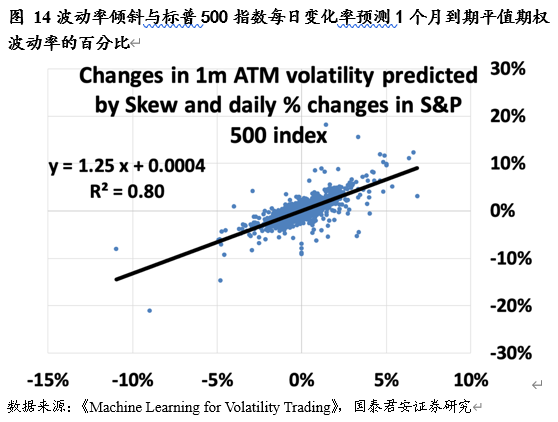
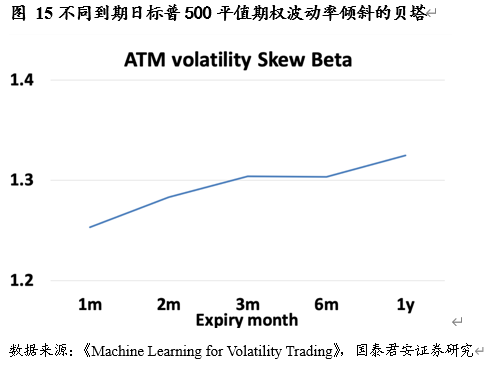
对于 Vega 风险,一个市场化的预测模型为:
𝑉𝑒𝑔𝑎风险 = 波动率倾斜 × 对应标的价格变化( 𝐷𝑒𝑙𝑡𝑎)们可以通过加入波动率倾斜 beta 来对 Delta 导致的 Vega 风险进行有效的对冲。
几十年来,学界与业界提出并完善的波动率模型常常使人感到眼花缭乱。
如何选择正确的模型(及参数)是一个非常重要的问题。Sepp 提出的机器学习模型有效地简化了这个流程。
Sepp 认为波动率具有很强的特征性。对于不同类的资产而言,它们的波动性往往有很大的区别。另一方面,同一个标的在不同的时间点也可能有不同的波动率。这让我们无法得到一个有效且通用的波动率预测模型。
基于以上的前提, Sepp 将训练数据进行了聚合与分类,并周期性地在不同时间对他的模型进行训练。在完成训练之后, Sepp 使用了模型盈亏等指标来提供反馈并改善模型。
对于模型的选择, Sepp 认为奥卡姆剃刀是一个非常重要的原则:选择一个需要最少假设的答案。一个存在太多层或需要过多的假设的模型会是误差反馈变得低效。
以上的描述使 Sepp 提出的模型与搜索引擎高度相似。与 Sepp 的模型一样,搜索引擎也需要一个搜索的目标(波动率)、处理请求、给出预测。











