前言
课间在看手机的时候,看到蚂蚁老师在群里发了一个单子,关于Excel处理的200元单子,快速看了一下客户的需求,决定接单来做。
需求分析
做项目之前,我喜欢先分析具体的需求,接单后我就在群里向客户要了参考的文档,并跟他详细对接了一下需求,最终确定下来就是要批量刷新多个 Excel 文件中的数据透视表。
拿到这个需求之后,我依次打开看了客户提供的 Excel 文件,查看了具体的数据内容,在这个过程中,我也找到了解决问题的思路,就是更新每个透视表对应的数据源。
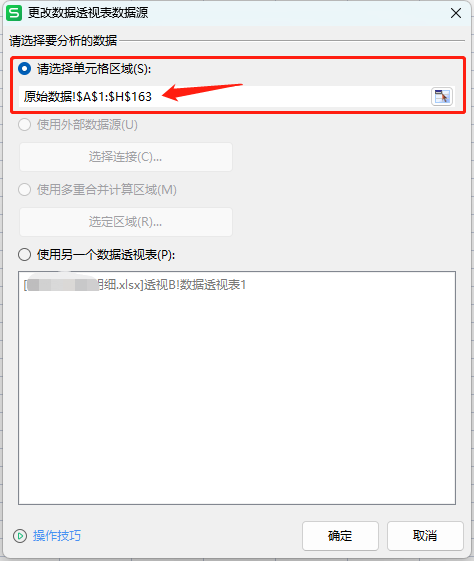
比较熟悉 Excel 的朋友可能会说,直接设置列范围,不要行范围就能覆盖全部数据,不用去更新。这个方法也是可行的,但是在透视表中会出现“(空白)”这个聚合项,可能会导致表格或者图表不好看,还要手动去取消这个选项。
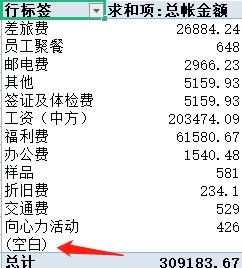
选中的空白单元格太多,会不会还有其他的问题,比如性能等,还有待研究。
所以最终我还是确定了处理方案,就是获取数据源的非空单元格内容,将数据范围更新到透视表的 Cache 中。
项目实施
梳理好了需求和思路之后,写代码的过程就变得很简单,围绕核心问题去展开就行了。
写代码的软件用的就是 PyCharm,Python 版本用的最新的3.11,表格处理用了xlwings和win32com两个库,win32com库只是用了其中的常量(这个也可以替换,懒得改了),主要处理还是xlwings。
1、获取数据源范围
首先要做的就是获取到数据源的范围,打开 Excel 文件并定位到数据源所在的 Sheet,就可以拿到数据范围,上代码:
# 获取数据范围,例如数据表的数据范围是”A1:AB100“,返回”表名!A1:AB100“
def get_data_range(wb, sheet_name: str) -> str:
raw_sheet = wb.sheets[sheet_name]
raw_data = raw_sheet.used_range
nrows = raw_data.last_cell.row
ncols = raw_data.last_cell.column
max_colname = idx_to_colname(ncols - 1)
return sheet_name + '!' + raw_sheet.range('A1', max_colname + str(nrows)).address
在获取数据源范围的时候,有个小细节,就是 Excel 的数据源列名使用字母表示的,而xlwings库拿到的是行列数,需要将列数转成字母,所以用了一个单独的方法idx_to_colname来处理:
# 列索引值转成列名,例如0转成A,1转成B,25转成Z,26转成AA,27转成AB,702转成ZZ,703转成AAA,704转成AAB
def idx_to_colname(idx: int) -> str:
base = 65 # ASCII code for 'A'
colname = ''
while idx >= 0:
colname = chr(base + idx % 26) + colname
idx = idx // 26 - 1
return colname
2、更新透视表的数据范围
有了数据范围,就可以去找到每一个透视表来更新它的数据源了:
# 遍历每一个sheet,刷新每一张数据透视表的数据范围
def refresh_pivot_table_data_range(wb, data_range: str) -> None:
for sheet in wb.sheets:
# 跳过原始数据表
if sheet.name == '原始数据':
continue
else:
for pivot_table in sheet.api.PivotTables():
# 更新数据透视表的数据范围
pivot_table.ChangePivotCache(
wb.api.PivotCaches().Create(SourceType=win32c.xlDatabase, SourceData=data_range,
Version=win32c.xlPivotTableVersion12))
# 刷新数据透视表
pivot_table.PivotCache().Refresh()
3、批量刷新多个Excel文件
单个文件的处理没问题之后,就可以遍历文件夹下所有 Excel 文件来依次处理了:
# 获取文件夹下所有xlsx文件
def get_excel_files(folder_path: str) -> list:
# 获取文件夹下所有文件
files = os.listdir(folder_path)
# 返回所有xlsx文件
return [os.path.join(folder_path, file) for file in files if file.endswith('.xlsx')]
处理单个文件的部分我也优化放到了一个函数里:
# 刷新单个excel文件下所有表的数据透视表
def refresh_file(app, file_path: str) -> None:
# 打开excel文件
wb = app.books.open(file_path)
data_range = get_data_range(wb, '原始数据')
print(data_range)
refresh_pivot_table_data_range(wb, data_range)
# 保存并关闭文件
wb.save()
wb.close()
4、程序执行入口函数
所有步骤的函数都写好之后,就可以放在入口函数中来执行了:
if __name__ == '__main__':
# 创建一个不可见的Excel应用程序
app = xw.App(visible=False, add_book=False)
# 指定文件夹名称
folder_name = '更新'
# 拼接文件夹路径
folder_path = os.path.join(os.getcwd(), folder_name)
# 获取文件夹下所有xlsx文件
files = get_excel_files(folder_path)
# 遍历每一个文件,刷新每一个文件下所有表的数据透视表
for file in files:
print('当前处理文件:' + file)
try:
refresh_file(app, file)
except Exception as e:
print(e)
finally:
print('文件处理完成:' + file)
# 关闭Excel应用程序
app.quit()
总结
这个项目的代码部分不是很难,需求也比较明确,所以代码的编写断断续续花了2个多小时就完成了。代码虽然简单,但是处理问题的思路很重要,需求搞清楚,就完成了80%。
最后,推荐蚂蚁老师的 Python 课程,学会了,你也可以向我一样优秀!:p









