
产品希望我们这边能够实现用户上传PDF、WORD、TXT之内得文本内容,然后用户可以根据附件名称或文件内容模糊查询文件信息,并可以在线查看文件内容。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
项目开发环境:
- 后台管理系统springboot+mybatis_plus+mysql+es
- 搜索引擎:elasticsearch7.9.3 +kibana图形化界面
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/yudao-cloud
- 视频教程:https://doc.iocoder.cn/video/
es+kibana的搭建这里就不介绍了,网上多的是
后台程序搭建也不介绍,这里有一点很重要,Java使用的连接es的包的版本一定要和es的版本对应上,不然你会有各种问题
第一步: 要用es实现文本附件内容的识别,需要先给es安装一个插件:Ingest Attachment Processor Plugin
这知识一个内容识别的插件,还有其它的例如OCR之类的其它插件,有兴趣的可以去搜一下了解一下
Ingest Attachment Processor Plugin是一个文本抽取插件,本质上是利用了Elasticsearch的ingest node功能,提供了关键的预处理器attachment。在安装目录下运行以下命令即可安装。
到es的安装文件bin目录下执行
elasticsearch-plugin install ingest-attachment
因为我们这里es是使用docker安装的,所以需要进入到es的docker镜像里面的bin目录下安装插件
[root@iZuf63d0pqnjrga4pi18udZ plugins]# docker exec -it es bash
[root@elasticsearch elasticsearch]# ls
LICENSE.txt NOTICE.txt README.asciidoc bin config data jdk lib logs modules plugins
[root@elasticsearch elasticsearch]# cd bin/
[root@elasticsearch bin]# ls
elasticsearch elasticsearch-certutil elasticsearch-croneval elasticsearch-env-from-file elasticsearch-migrate elasticsearch-plugin elasticsearch-setup-passwords elasticsearch-sql-cli elasticsearch-syskeygen x-pack-env x-pack-watcher-env
elasticsearch-certgen elasticsearch-cli elasticsearch-env elasticsearch-keystore elasticsearch-node elasticsearch-saml-metadata elasticsearch-shard elasticsearch-sql-cli-7.9.3.jar elasticsearch-users x-pack-security-env
[root@elasticsearch bin]# elasticsearch-plugin install ingest-attachment
-> Installing ingest-attachment
-> Downloading ingest-attachment from elastic
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.java2d.cmm.kcms
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.security.SecurityPermission createAccessControlContext
* java.security.SecurityPermission insertProvider
* java.security.SecurityPermission putProviderProperty.BC
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed ingest-attachment
显示installed 就表示安装完成了,然后重启es,不然第二步要报错
第二步:创建一个文本抽取的管道
主要是用于将上传的附件转换成文本内容,支持(word,PDF,txt,excel没试,应该也支持)
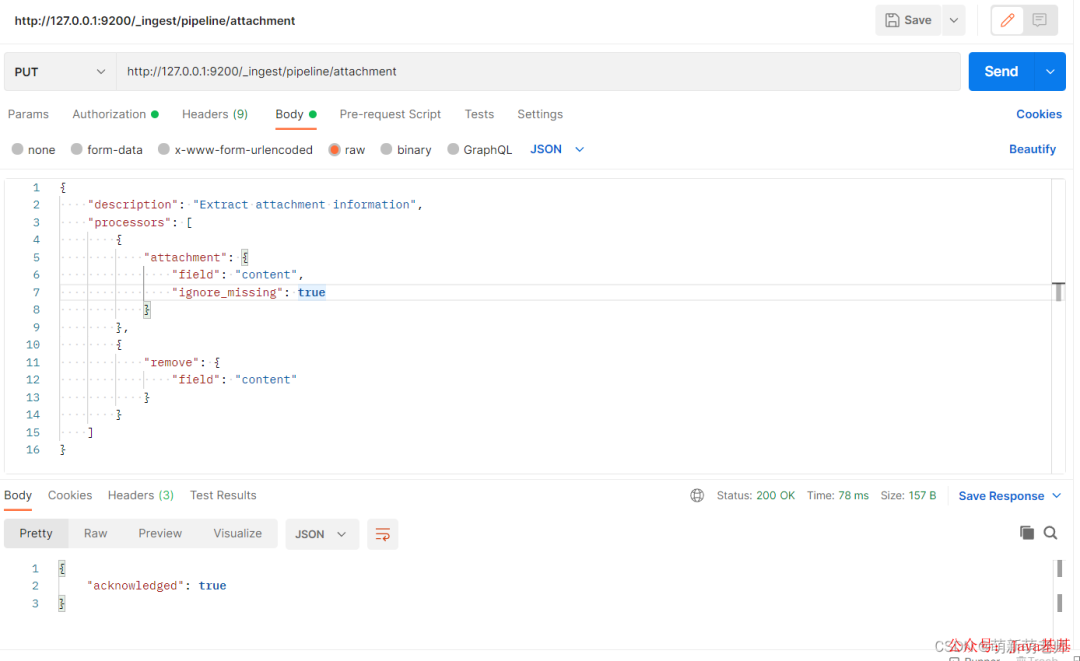
{
"description": "Extract attachment information",
"processors": [
{
"attachment": {
"field": "content",
"ignore_missing": true
}
},
{
"remove": {
"field": "content"
}
}
]
}
第三步:定义我们内容存储的索引
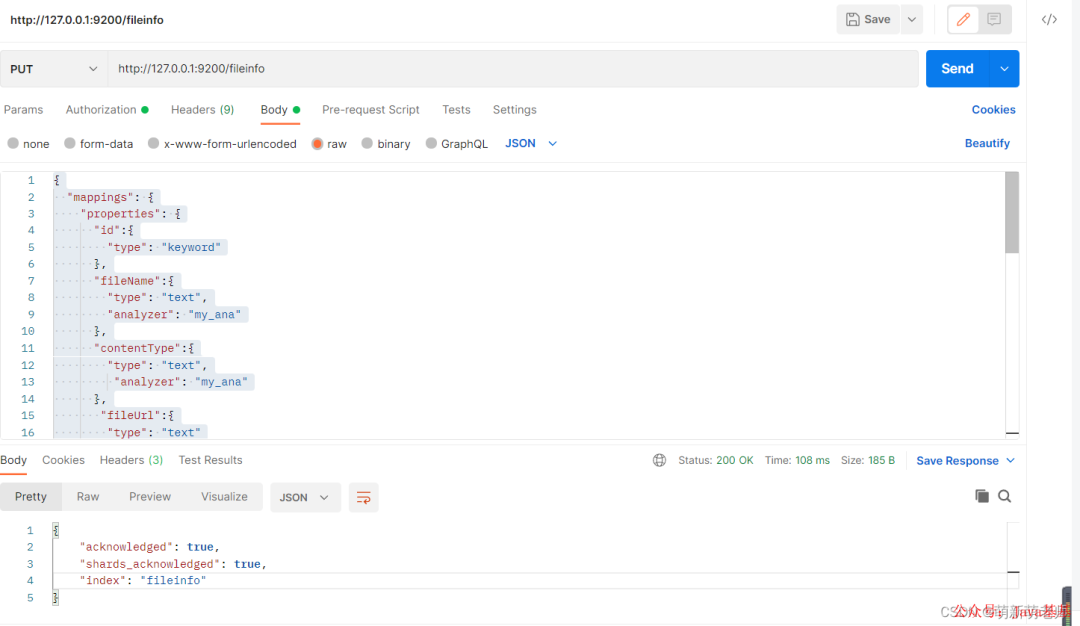
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"fileName":{
"type": "text",
"analyzer": "my_ana"
},
"contentType":{
"type": "text",
"analyzer": "my_ana"
},
"fileUrl":{
"type": "text"
},
"attachment": {
"properties": {
"content":{
"type": "text",
"analyzer": "my_ana"
}
}
}
}
},
"settings": {
"analysis": {
"filter": {
"jieba_stop": {
"type": "stop",
"stopwords_path": "stopword/stopwords.txt"
},
"jieba_synonym": {
"type": "synonym",
"synonyms_path": "synonym/synonyms.txt"
}
},
"analyzer": {
"my_ana": {
"tokenizer": "jieba_index",
"filter": [
"lowercase",
"jieba_stop",
"jieba_synonym"
]
}
}
}
}
}
- setting:索引的配置信息,这边定义了一个分词(使用的是jieba的分词)
“
注意:内容检索的是attachment.content字段,一定要使用分词,不使用分词的话,检索会检索不出来内容
第四步:测试
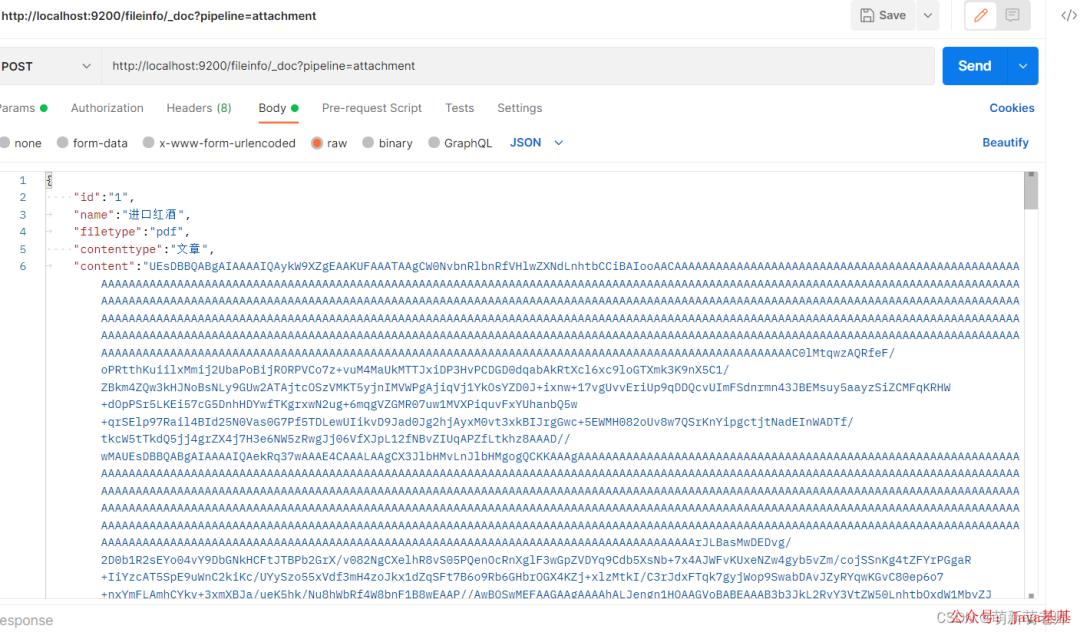
{
"id":"1",
"name":"进口红酒",
"filetype":"pdf",
"contenttype":"文章",
"content":"文章内容"
}
测试内容需要将附件转换成base64格式
在线转换文件的地址:
“
https://www.zhangxinxu.com/sp/base64.html
查询刚刚上传的文件:
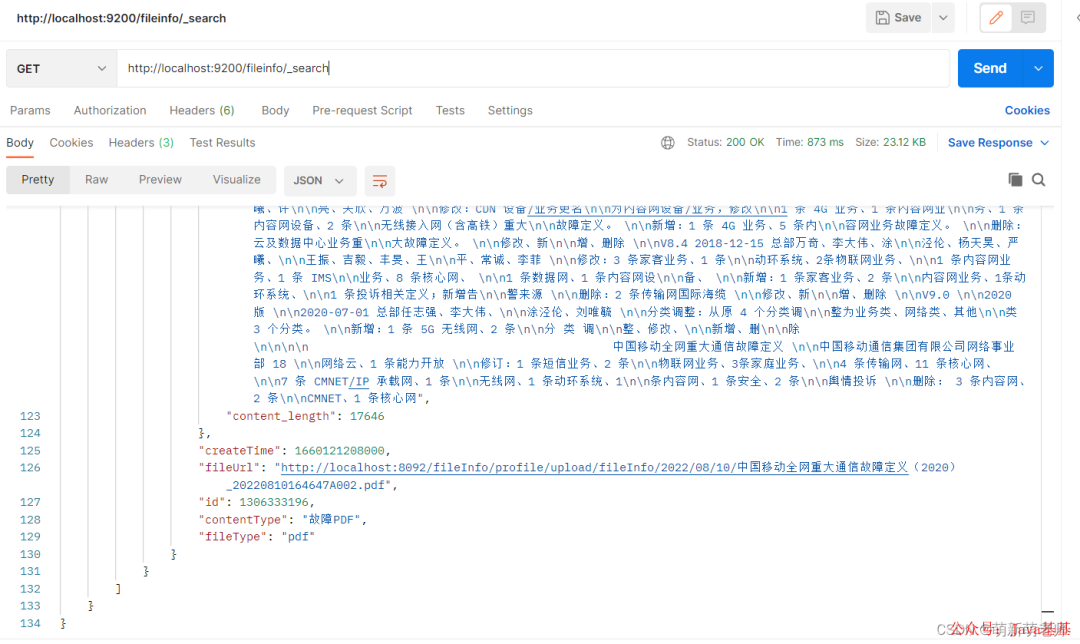
{
"took": 861,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "lkPEgYIBz3NlBKQzXYX9",
"_score": 1.0,
"_source": {
"fileName": "测试_20220809164145A002.docx",
"updateTime": 1660034506000,
"attachment": {
"date": "2022-08-09T01:38:00Z",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"author": "DELL",
"language": "lt",
"content": "内容",
"content_length": 2572
},
"createTime": 1660034506000,
"fileUrl": "http://localhost:8092/fileInfo/profile/upload/fileInfo/2022/08/09/测试_20220809164145A002.docx",
"id": 1306333192,
"contentType": "文章",
"fileType": "docx"
}
},
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "mUPHgYIBz3NlBKQzwIVW",
"_score": 1.0,
"_source": {
"fileName": "测试_20220809164527A001.docx",
"updateTime": 1660034728000,
"attachment": {
"date": "2022-08-09T01:38:00Z",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"author": "DELL",
"language": "lt",
"content": "内容",
"content_length": 2572
},
"createTime": 1660034728000,
"fileUrl": "http://localhost:8092/fileInfo/profile/upload/fileInfo/2022/08/09/测试_20220809164527A001.docx",
"id": 1306333193,
"contentType": "文章",
"fileType": "docx"
}
},
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "JDqshoIBbkTNu1UgkzFK",
"_score": 1.0,
"_source": {
"fileName": "txt测试_20220810153351A001.txt",
"updateTime": 1660116831000,
"attachment": {
"content_type": "text/plain; charset=UTF-8",
"language": "lt",
"content": "内容",
"content_length": 804
},
"createTime": 1660116831000,
"fileUrl": "http://localhost:8092/fileInfo/profile/upload/fileInfo/2022/08/10/txt测试_20220810153351A001.txt",
"id": 1306333194,
"contentType": "告示",
"fileType": "txt"
}
}
]
}
}
我们调用上传的接口,可以看到文本内容已经抽取到es里面了,后面就可以直接分词检索内容,高亮显示了
介绍下代码实现逻辑:文件上传,数据库存储附件信息和附件上传地址;调用es实现文本内容抽取,将抽取的内容放到对应索引下;提供小程序全文检索的api实现根据文件名称关键词联想,文件名称内容全文检索模糊匹配,并高亮显示分词匹配字段;直接贴代码
yml配置文件:
# 数据源配置
spring:
# 服务模块
devtools:
restart:
# 热部署开关
enabled: true
# 搜索引擎
elasticsearch:
rest:
url: 127.0.0.1
uris: 127.0.0.1:9200
connection-timeout: 1000
read-timeout: 3000
username: elastic
password: 123456
elsticsearchConfig(连接配置)
package com.yj.rselasticsearch.domain.config;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.time.Duration;
@Configuration
public class ElasticsearchConfig {
@Value("${spring.elasticsearch.rest.url}")
private String edUrl;
@Value("${spring.elasticsearch.rest.username}")
private String userName;
@Value("${spring.elasticsearch.rest.password}")
private String password;
@Bean
public RestHighLevelClient restHighLevelClient() {
//设置连接的用户名密码
final BasicCredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost(edUrl, 9200,"http"))
.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.disableAuthCaching();
//保持连接池处于链接状态,该bug曾导致es一段时间没使用,第一次连接访问超时
httpClientBuilder.setKeepAliveStrategy(((response, context) -> Duration.ofMinutes(5).toMillis()));
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
})
);
return client;
}
}
文件上传保存文件信息并抽取内容到es
实体对象FileInfo
package com.yj.common.core.domain.entity;
import com.baomidou.mybatisplus.annotation.TableField;
import com.yj.common.core.domain.BaseEntity;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
@Setter
@Getter
@Document(indexName = "fileinfo",createIndex = false)
public class FileInfo {
/**
* 主键
*/
@Field(name = "id", type = FieldType.Integer)
private Integer id;
/**
* 文件名称
*/
@Field(name = "fileName", type = FieldType.Text,analyzer = "jieba_index",searchAnalyzer = "jieba_index")
private String fileName;
/**
* 文件类型
*/
@Field
(name = "fileType", type = FieldType.Keyword)
private String fileType;
/**
* 内容类型
*/
@Field(name = "contentType", type = FieldType.Text)
private String contentType;
/**
* 附件内容
*/
@Field(name = "attachment.content", type = FieldType.Text,analyzer = "jieba_index",searchAnalyzer = "jieba_index")
@TableField(exist = false)
private String content;
/**
* 文件地址
*/
@Field(name = "fileUrl", type = FieldType.Text)
private String fileUrl;
/**
* 创建时间
*/
private Date createTime;
/**
* 更新时间
*/
private Date updateTime;
}
controller类
package com.yj.rselasticsearch.controller;
import com.yj.common.core.controller.BaseController;
import com.yj.common.core.domain.AjaxResult;
import com.yj.common.core.domain.entity.FileInfo;
import com.yj.rselasticsearch.service.FileInfoService;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
/**
* (file_info)表控制层
*
* @author xxxxx
*/
@RestController
@RequestMapping("/fileInfo")
public class FileInfoController extends BaseController {
/**
* 服务对象
*/
@Resource
private FileInfoService fileInfoService;
@PutMapping("uploadFile")
public AjaxResult uploadFile(String contentType, MultipartFile file) {
return fileInfoService.uploadFileInfo(contentType,file);
}
}
serviceImpl实现类
package com.yj.rselasticsearch.service.impl;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.yj.common.config.RuoYiConfig;
import com.yj.common.core.domain.AjaxResult;
import com.yj.common.utils.FastUtils;
import com.yj.common.utils.StringUtils;
import com.yj.common.utils.file.FileUploadUtils;
import com.yj.common.utils.file.FileUtils;
import com.yj.framework.config.ServerConfig;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import com.yj.common.core.domain.entity.FileInfo;
import com.yj.rselasticsearch.mapper.FileInfoMapper;
import com.yj.rselasticsearch.service.FileInfoService;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Base64;
@Service
@Slf4j
public class FileInfoServiceImpl implements FileInfoService{
@Resource
private ServerConfig serverConfig;
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@Resource
private FileInfoMapper fileInfoMapper;
/**
* 上传文件并进行文件内容识别上传到es
* @param contentType
* @param file
* @return
*/
@Override
public AjaxResult uploadFileInfo(String contentType, MultipartFile file) {
if (FastUtils.checkNullOrEmpty(contentType,file)){
return AjaxResult.error("请求参数不能为空");
}
try {
// 上传文件路径
String filePath = RuoYiConfig.getUploadPath() + "/fileInfo";
FileInfo fileInfo = new FileInfo();
// 上传并返回新文件名称
String fileName = FileUploadUtils.upload(filePath, file);
String prefix = fileName.substring(fileName.lastIndexOf(".")+1);
File files = File.createTempFile(fileName, prefix);
file.transferTo(files);
String url = serverConfig.getUrl() + "/fileInfo" + fileName;
fileInfo.setFileName(FileUtils.getName(fileName));
fileInfo.setFileType(prefix);
fileInfo.setFileUrl(url);
fileInfo.setContentType(contentType);
int result = fileInfoMapper.insertSelective(fileInfo);
if (result > 0) {
fileInfo = fileInfoMapper.selectOne(new LambdaQueryWrapper().eq(FileInfo::getFileUrl,fileInfo.getFileUrl()));
byte[] bytes = getContent(files);
String base64 = Base64.getEncoder().encodeToString(bytes);
fileInfo.setContent(base64);
IndexRequest indexRequest = new IndexRequest("fileinfo");
//上传同时,使用attachment pipline进行提取文件
indexRequest.source(JSON.toJSONString(fileInfo), XContentType.JSON);
indexRequest.setPipeline("attachment");
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
log.info("indexResponse:" + indexResponse);
}
AjaxResult ajax = AjaxResult.success(fileInfo);
return ajax;
} catch (Exception e) {
return AjaxResult.error(e.getMessage());
}
}
/**
* 文件转base64
*
* @param file
* @return
* @throws IOException
*/
private byte[] getContent(File file) throws IOException {
long fileSize = file.length();
if (fileSize > Integer.MAX_VALUE) {
log.info("file too big...");
return null;
}
FileInputStream fi = new FileInputStream(file);
byte[] buffer = new byte[(int) fileSize];
int offset = 0;
int numRead = 0;
while (offset && (numRead = fi.read(buffer, offset, buffer.length - offset)) >= 0) {
offset += numRead;
}
// 确保所有数据均被读取
if (offset != buffer.length) {
throw new ServiceException("Could not completely read file "
+ file.getName());
}
fi.close();
return buffer;
}
}
高亮分词检索
参数请求WarningInfoDto
package com.yj.rselasticsearch.domain.dto;
import com.yj.common.core.domain.entity.WarningInfo;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.util.List;
/**
* 前端请求数据传输
* WarningInfo
* @author luoY
*/
@Data
@ApiModel(value ="WarningInfoDto",description = "告警信息")
public class WarningInfoDto{
/**
* 页数
*/
@ApiModelProperty("页数")
private Integer pageIndex;
/**
* 每页数量
*/
@ApiModelProperty("每页数量")
private Integer pageSize;
/**
* 查询关键词
*/
@ApiModelProperty("查询关键词")
private String keyword;
/**
* 内容类型
*/
private List contentType;
/**
* 用户手机号
*/
private String phone;
}
controller类
package com.yj.rselasticsearch.controller;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.yj.common.core.controller.BaseController;
import com.yj.common.core.domain.AjaxResult;
import com.yj.common.core.domain.entity.FileInfo;
import com.yj.common.core.domain.entity.WarningInfo;
import com.yj.rselasticsearch.service.ElasticsearchService;
import com.yj.rselasticsearch.service.WarningInfoService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiImplicitParams;
import io.swagger.annotations.ApiOperation;
import org.springframework.web.bind.annotation.*;
import com.yj.rselasticsearch.domain.dto.WarningInfoDto;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.List;
/**
* es搜索引擎
*
* @author luoy
*/
@Api("搜索引擎")
@RestController
@RequestMapping("es")
public class ElasticsearchController extends BaseController {
@Resource
private ElasticsearchService elasticsearchService;
/**
* 告警信息关键词联想
*
* @param warningInfoDto
* @return
*/
@ApiOperation("关键词联想")
@ApiImplicitParams({
@ApiImplicitParam(name = "contenttype", value = "文档类型", required = true, dataType = "String", dataTypeClass = String.class),
@ApiImplicitParam(name = "keyword", value = "关键词", required = true, dataType = "String", dataTypeClass = String.class)
})
@PostMapping("getAssociationalWordDoc")
public AjaxResult getAssociationalWordDoc(@RequestBody WarningInfoDto warningInfoDto, HttpServletRequest request) {
List words = elasticsearchService.getAssociationalWordOther(warningInfoDto,request);
return AjaxResult.success(words);
}
/**
* 告警信息高亮分词分页查询
*
* @param warningInfoDto
* @return
*/
@ApiOperation("高亮分词分页查询")
@ApiImplicitParams({
@ApiImplicitParam(name = "keyword", value = "关键词", required = true, dataType = "String", dataTypeClass = String.class),
@ApiImplicitParam(name = "pageIndex", value = "页码", required = true, dataType = "Integer", dataTypeClass = Integer.class),
@ApiImplicitParam(name = "pageSize", value = "页数", required = true, dataType = "Integer", dataTypeClass = Integer.class),
@ApiImplicitParam(name = "contenttype", value = "文档类型", required = true, dataType = "String", dataTypeClass = String.class)
})
@PostMapping("queryHighLightWordDoc")
public AjaxResult queryHighLightWordDoc(@RequestBody WarningInfoDto warningInfoDto,HttpServletRequest request) {
IPage warningInfoListPage = elasticsearchService.queryHighLightWordOther(warningInfoDto,request);
return AjaxResult.success(warningInfoListPage);
}
}
serviceImpl实现类
package com.yj.rselasticsearch.service.impl;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.yj.common.constant.DataConstants;
import com.yj.common.constant.HttpStatus;
import com.yj.common.core.domain.entity.FileInfo;
import com.yj.common.core.domain.entity.WarningInfo;
import com.yj.common.core.domain.entity.WhiteList;
import com.yj.common.core.redis.RedisCache;
import com.yj.common.exception.ServiceException;
import com.yj.common.utils.FastUtils;
import com.yj.rselasticsearch.domain.dto.RetrievalRecordDto;
import com.yj.rselasticsearch.domain.dto.WarningInfoDto;
import com.yj.rselasticsearch.domain.vo.MemberVo;
import com.yj.rselasticsearch.service.*;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.*;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.*;
import java.util.stream.Collectors;
@Service
@Slf4j
public class ElasticsearchServiceImpl implements ElasticsearchService {
@Resource
private WhiteListService whiteListService;
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@Autowired
private RedisCache redisCache;
@Resource
private TokenService tokenService;
/**
* 文档信息关键词联想(根据输入框的词语联想文件名称)
*
* @param warningInfoDto
* @return
*/
@Override
public List getAssociationalWordOther(WarningInfoDto warningInfoDto, HttpServletRequest request) {
//需要查询的字段
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchBoolPrefixQuery("fileName", warningInfoDto.getKeyword()));
//contentType标签内容过滤
boolQueryBuilder.must(QueryBuilders.termsQuery("contentType", warningInfoDto.getContentType()));
//构建高亮查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightFields(
new HighlightBuilder.Field("fileName")
)
.withHighlightBuilder(new HighlightBuilder().preTags("").postTags(""))
.build();
//查询
SearchHits search = null;
try {
search = elasticsearchRestTemplate.search(searchQuery, FileInfo.class);
} catch (Exception ex) {
ex.printStackTrace();
throw new ServiceException(String.format("操作错误,请联系管理员!%s", ex.getMessage()));
}
//设置一个最后需要返回的实体类集合
List resultList = new LinkedList<>();
//遍历返回的内容进行处理
for (org.springframework.data.elasticsearch.core.SearchHit searchHit : search.getSearchHits()) {
//高亮的内容
Map> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent().setFileName(highlightFields.get("fileName") == null ? searchHit.getContent().getFileName() : highlightFields.get("fileName").get(0));
if (highlightFields.get("fileName") != null) {
resultList.add(searchHit.getContent().getFileName());
}
}
//list去重
List newResult = null;
if (!FastUtils.checkNullOrEmpty(resultList)) {
if (resultList.size() > 9) {
newResult = resultList.stream().distinct().collect(Collectors.toList()).subList(0, 9);
} else {
newResult = resultList.stream().distinct().collect(Collectors.toList());
}
}
return newResult;
}
/**
* 高亮分词搜索其它类型文档
*
* @param warningInfoDto
* @param request
* @return
*/
@Override
public IPage queryHighLightWordOther(WarningInfoDto warningInfoDto, HttpServletRequest request) {
//分页
Pageable pageable = PageRequest.of(warningInfoDto.getPageIndex() - 1, warningInfoDto.getPageSize());
//需要查询的字段,根据输入的内容分词全文检索fileName和content字段
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchBoolPrefixQuery("fileName", warningInfoDto.getKeyword()))
.should(QueryBuilders.matchBoolPrefixQuery("attachment.content", warningInfoDto.getKeyword()));
//contentType标签内容过滤
boolQueryBuilder.must(QueryBuilders.termsQuery("contentType", warningInfoDto.getContentType()));
//构建高亮查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightFields(
new HighlightBuilder.Field("fileName"), new HighlightBuilder.Field("attachment.content")
)
.withHighlightBuilder(new HighlightBuilder().preTags("").postTags(""))
.build();
//查询
SearchHits search = null;
try {
search = elasticsearchRestTemplate.search(searchQuery, FileInfo.class);
} catch (Exception ex) {
ex.printStackTrace();
throw new ServiceException(String.format("操作错误,请联系管理员!%s", ex.getMessage()));
}
//设置一个最后需要返回的实体类集合
List resultList = new LinkedList<>();
//遍历返回的内容进行处理
for (org.springframework.data.elasticsearch.core.SearchHit searchHit : search.getSearchHits()) {
//高亮的内容
Map> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent().setFileName(highlightFields.get("fileName") == null ? searchHit.getContent().getFileName() : highlightFields.get("fileName").get(0));
searchHit.getContent().setContent(highlightFields.get("content") == null ? searchHit.getContent().getContent() : highlightFields.get("content").get(0));
resultList.add(searchHit.getContent());
}
//手动分页返回信息
IPage warningInfoIPage = new Page<>();
warningInfoIPage.setTotal(search.getTotalHits());
warningInfoIPage.setRecords(resultList);
warningInfoIPage.setCurrent(warningInfoDto.getPageIndex());
warningInfoIPage.setSize(warningInfoDto.getPageSize());
warningInfoIPage.setPages(warningInfoIPage.getTotal() % warningInfoDto.getPageSize());
return warningInfoIPage;
}
}
代码测试:
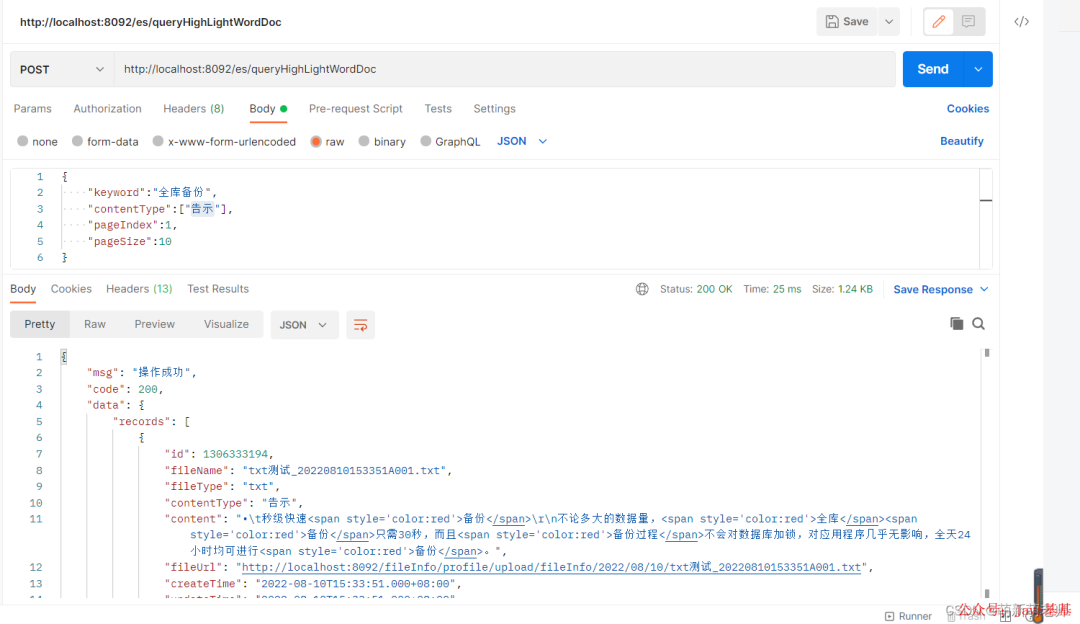
--请求jason
{
"keyword":"全库备份",
"contentType":["告示"],
"pageIndex":1,
"pageSize":10
}
--响应
{
"msg": "操作成功",
"code": 200,
"data": {
"records": [
{
"id": 1306333194,
"fileName": "txt测试_20220810153351A001.txt",
"fileType": "txt",
"contentType": "告示",
"content": "•\t秒级快速备份\r\n不论多大的数据量,全库备份只需30秒,而且备份过程不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。",
"fileUrl": "http://localhost:8092/fileInfo/profile/upload/fileInfo/2022/08/10/txt测试_20220810153351A001.txt",
"createTime": "2022-08-10T15:33:51.000+08:00",
"updateTime": "2022-08-10T15:33:51.000+08:00"
}
],
"total": 1,
"size": 10,
"current": 1,
"orders": [],
"optimizeCountSql": true,
"searchCount": true,
"countId": null,
"maxLimit": null,
"pages": 1
}
}
返回的内容将分词检索到匹配的内容,并将匹配的词高亮显示。








