不少学术论文对深度学习模型进行了深度探讨,但并没有展示出完整的情况。有趣的是,即使在 NLP 的案例中,一些人更倾向于将 GPT 模型的重大突破归功于“更多的数据和计算能力”,而非“更优秀的机器学习研究”。
本文旨在消除可能存在的混淆,提供一个中立无偏的视角,并借助来自学术界和工业界的可信赖数据和资源进行阐述。具体来说,本文将讨论以下主题:
- 如何通过为你的案例和数据集选择最佳模型来节省时间和金钱。
深度学习与统计学
在讨论各种预测模型的发展过程时,Makridakis竞赛(又名M竞赛)提供了宝贵的见解。M竞赛是一系列的大型挑战赛,旨在呈现时间序列预测的最新进展。近期,Makridakis等人发表了一篇新论文,总结了前五届M竞赛的预测状况,同时提供了统计、机器学习和深度学习预测模型的广泛基准数据。然而,我们将在文章的后部分讨论这篇论文的一些局限性。
基准设置
传统上,Makridakis 及其同事会在每次M竞赛结束后发表一篇总结论文。然而,这是他们首次在实验中纳入深度学习模型。为什么会这样?与自然语言处理(NLP)不同,深度学习(DL)预测模型在2018-2019年间才成熟到可以挑战传统预测模型。实际上,在2018年的M4竞赛中,机器学习/深度学习模型的排名垫底。
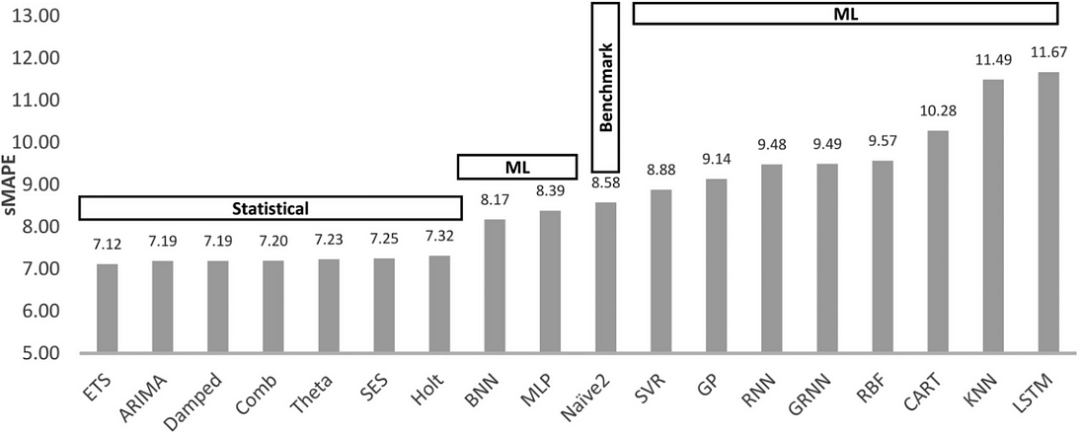
现在,让我们看看新论文中使用的DL/ML模型:
- 多层感知器(Multi-layer Perceptron (MLP)):我们熟悉的前馈网络。
- 波浪网(WaveNet):一个结合卷积层的自回归神经网络(2016)。
- 转换模型(Transformer):最初的Transformer,于2017年推出。
- DeepAR:亚马逊第一个成功的自动回归网络,结合了LSTM(2017)。
注意:深度学习模型现在已经不再是最先进的(State-of-the-Art,SOTA)技术(稍后将详细讨论)。另外,多层感知机(MLP)被视为机器学习模型,而非“深度”模型。
基准测试中的统计模型包括ARIMA和ETS(指数平滑)——这两种模型都是广为人知且经过严格验证的模型。
此外,
- ML/DL模型首先通过超参数调整进行了微调。统计模型则以逐个时间序列的方式进行训练。相反,DL模型是全局模型(在数据集的所有时间序列上进行训练)。因此,它们能够利用交叉学习的优势。
- 作者采用了集成方法:从深度学习模型中创建了一个Ensemble-DL模型,而从统计模型中创建了一个Ensemble-S模型。集成方法采用了预测结果的中位数。
- Ensemble-DL由200个模型组成,每个类别(DeepAR、Transformer、WaveNet和MLP)有50个模型。
- 该研究使用了M3数据集:首先,作者对1,045个时间序列进行了测试,然后对整个数据集(3,003个时间序列)进行了测试。
- 作者使用了MASE(均方绝对缩放误差)和SMAPE(平均绝对百分比误差)等指标来衡量预测的准确性。这些误差度量标准在预测中常被使用。
接下来,我们提供了一个从基准得到的结果和结论的总结。
深度学习更好
作者的结论是,平均而言,DL模型的表现优于统计模型。结果显示在图2中:
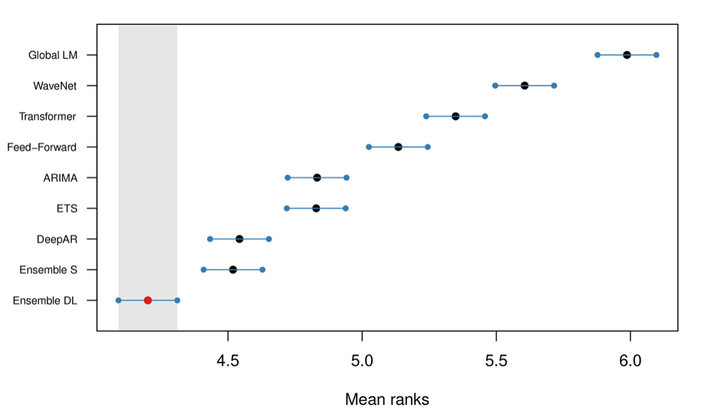 图2:所有模型的平均排名和95%置信区间,使用sMAPE进行排名
图2:所有模型的平均排名和95%置信区间,使用sMAPE进行排名Ensemble-DL模型的表现明显优于Ensemble-S。另外,DeepAR也取得了与Ensemble-S非常相似的结果。有趣的是,图2显示,尽管Ensemble-DL胜过Ensemble-S,但只有DeepAR胜过单个统计模型。这是为什么呢?我们将在文章的后面回答这个问题。
深度学习昂贵
深度学习模型需要大量的时间来训练(和金钱)。这是意料之中的事。结果显示在图3中:
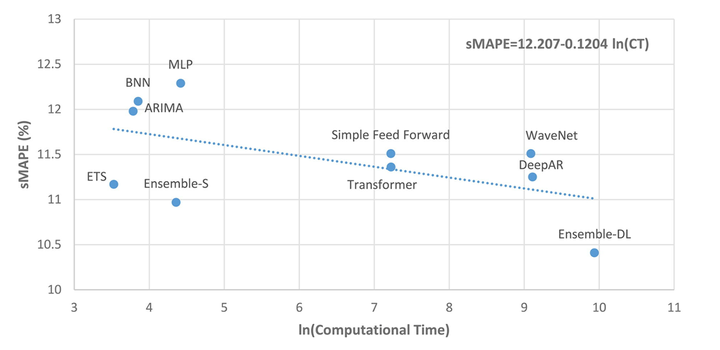 图3:SMAPE与计算时间
图3:SMAPE与计算时间ln(CT)为零对应的计算时间约为1分钟,而ln(CT)为2、4、6、8和10分别对应约7分钟、1小时、7小时、2天和15天
计算上的差异是很大的。因此,降低10%的预测误差需要大约15天的额外计算时间(Ensemble-DL)。虽然这个数字看起来很大,但有一些事情需要考虑:
- 如果在集合中使用较少的模型,Ensemble-DL的计算时间可以大大减少。这显示在图4中:
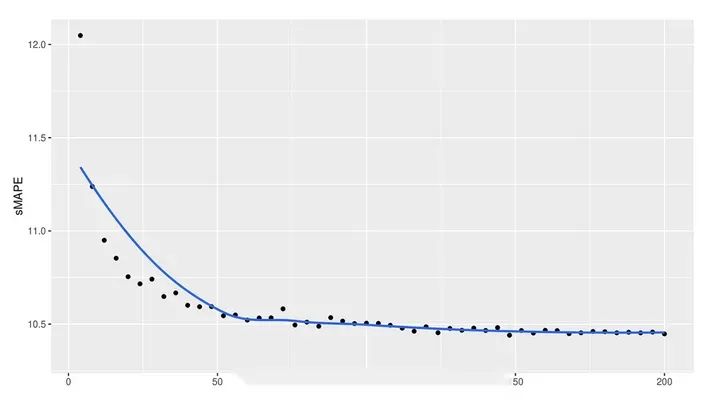
之前提到,Ensemble-DL模型是200个DL模型的集合体。图4显示,75个模型可以达到与200个模型相当的精度,而计算成本只有三分之一。如果使用更巧妙的方法来做合集,这个数字还可以进一步减少。最后,本文没有探讨深度学习模型的转移学习能力。我们以后也会讨论这个问题。
集成模型
集成模型的强大是无可争议的(见图2,图3)。无论是深度学习的集成模型(Ensemble-DL)还是统计学习的集成模型(Ensemble-SL),都是表现最佳的模型。这种思想的基础是每个单独的模型都擅长捕捉不同的时间动态。将它们的预测结果结合起来能够识别复杂的模式并进行准确的推断。
短期 vs 长期
作者们研究了模型在短期预测与长期预测能力上是否存在差异。结果显示的确存在差异。图5详细展示了每个模型在每个预测视野上的准确度。例如,第1列显示了一步预测的误差。类似地,第18列显示了第18步预测的误差。
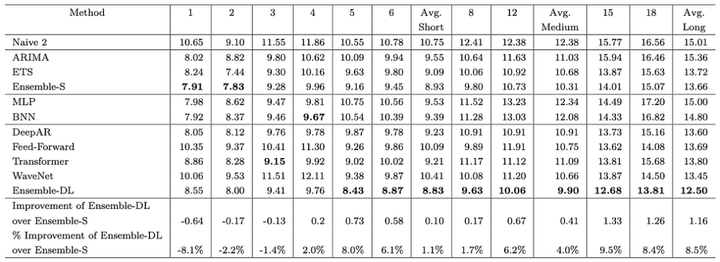 图5:1045系列的每个模型的sMAPE误差--越低越好
图5:1045系列的每个模型的sMAPE误差--越低越好这里有3个关键的观察:
首先,长期预测不如短期预测准确(这并不奇怪)。在前4个水平线上,统计模型获胜。除此之外,深度学习模型开始变得更好,Ensemble-DL获胜。具体来说,在第一个水平线上,Ensemble-S的准确度要高8.1%。然而,在最后一个水平线上,Ensemble-DL的准确度要高8.5%。
如果你想一想,这是有道理的:
- 统计模型是自动回归的。随着预测范围的增加,误差会不断累积。
- 相反,深度学习模型是多输出模型。因此,他们的预测误差分布在整个预测序列中。
- 唯一的DL自回归模型是DeepAR。这就是为什么DeepAR在第一个水平线上表现得非常好,与其他DL模型相反。
数据重要性
在之前的实验中,作者只使用了M3数据集中的1045个时间序列。接下来,作者使用完整的数据集(3,003个序列)重新进行了实验。他们还分析了每个水平线的预测损失。结果显示在图6中:
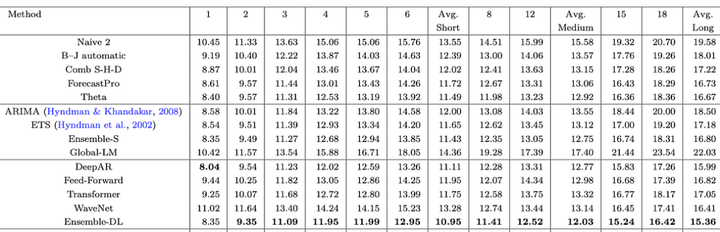 图6:3003系列每个模型的sMAPE误差
图6:3003系列每个模型的sMAPE误差现在,Ensemble-DL和Ensemble-S之间的差距缩小了。在第一个水平线上,统计模型与深度学习模型相匹配,但在那之后,Ensemble-DL的表现超过了它们。
让我们进一步分析Ensemble-DL和Ensemble-S之间的差异:
 图7:Ensemble-DL对Ensemble-S的改进百分比
图7:Ensemble-DL对Ensemble-S的改进百分比随着预测步骤的增加,深度学习模型的表现超越了统计集成模型。
趋势与季节性
最后,作者们研究了统计模型和深度学习模型如何处理时间序列的重要特性,比如趋势和季节性。为了实现这一点,作者们采用了[5]的方法。具体来说,他们拟合了一个多元线性回归模型,该模型将sMAPE误差与五个关键的时间序列特性关联起来:可预测性(错误的随机性)、趋势、季节性、线性、稳定性(决定数据正态性的最佳Box-Cox参数转换)。结果如图8所示:
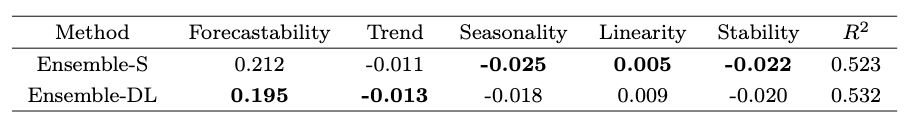 图8:不同指标的线性回归系数。数值越低越好
图8:不同指标的线性回归系数。数值越低越好我们可以观察到:
- 深度学习模型在处理噪声大、有趋势以及非线性数据方面表现更佳。
- 对于具有线性关系的季节性和低方差数据,统计模型更为合适。
这些洞察无比宝贵。因此,在为你的应用案例选择合适的模型之前,进行深入的探索性数据分析(EDA)并理解数据的本质是至关重要的。
以下内容重复,跳过阅读!跳过阅读!感谢!深度学习在 NLP 领域取得了显著进展。由于时间序列本质上也是呈现出序列性,如果将预训练的转换器(transformers)模型应用在时间序列预测上,结果将会如何呢?
不少学术论文对深度学习模型进行了深度探讨,但并没有展示出完整的情况。有趣的是,即使在 NLP 的案例中,一些人更倾向于将 GPT 模型的重大突破归功于“更多的数据和计算能力”,而非“更优秀的机器学习研究”。
本文旨在消除可能存在的混淆,提供一个中立无偏的视角,并借助来自学术界和工业界的可信赖数据和资源进行阐述。具体来说,本文将讨论以下主题:
- 如何通过为你的案例和数据集选择最佳模型来节省时间和金钱。
深度学习与统计学
在讨论各种预测模型的发展过程时,Makridakis竞赛(又名M竞赛)提供了宝贵的见解。M竞赛是一系列的大型挑战赛,旨在呈现时间序列预测的最新进展。近期,Makridakis等人发表了一篇新论文,总结了前五届M竞赛的预测状况,同时提供了统计、机器学习和深度学习预测模型的广泛基准数据。然而,我们将在文章的后部分讨论这篇论文的一些局限性。
基准设置
传统上,Makridakis 及其同事会在每次M竞赛结束后发表一篇总结论文。然而,这是他们首次在实验中纳入深度学习模型。为什么会这样?与自然语言处理(NLP)不同,深度学习(DL)预测模型在2018-2019年间才成熟到可以挑战传统预测模型。实际上,在2018年的M4竞赛中,机器学习/深度学习模型的排名垫底。
现在,让我们看看新论文中使用的DL/ML模型:
- 多层感知器(Multi-layer Perceptron (MLP)):我们熟悉的前馈网络。
- 波浪网(WaveNet):一个结合卷积层的自回归神经网络(2016)。
- 转换模型(Transformer):最初的Transformer,于2017年推出。
- DeepAR:亚马逊第一个成功的自动回归网络,结合了LSTM(2017)。
注意:深度学习模型现在已经不再是最先进的(State-of-the-Art,SOTA)技术(稍后将详细讨论)。另外,多层感知机(MLP)被视为机器学习模型,而非“深度”模型。
基准测试中的统计模型包括ARIMA和ETS(指数平滑)——这两种模型都是广为人知且经过严格验证的模型。
此外,
- ML/DL模型首先通过超参数调整进行了微调。统计模型则以逐个时间序列的方式进行训练。相反,DL模型是全局模型(在数据集的所有时间序列上进行训练)。因此,它们能够利用交叉学习的优势。
- 作者采用了集成方法:从深度学习模型中创建了一个Ensemble-DL模型,而从统计模型中创建了一个Ensemble-S模型。集成方法采用了预测结果的中位数。
- Ensemble-DL由200个模型组成,每个类别(DeepAR、Transformer、WaveNet和MLP)有50个模型。
- 该研究使用了M3数据集:首先,作者对1,045个时间序列进行了测试,然后对整个数据集(3,003个时间序列)进行了测试。
- 作者使用了MASE(均方绝对缩放误差)和SMAPE(平均绝对百分比误差)等指标来衡量预测的准确性。这些误差度量标准在预测中常被使用。
接下来,我们提供了一个从基准得到的结果和结论的总结。
深度学习更好
作者的结论是,平均而言,DL模型的表现优于统计模型。结果显示在图2中:
图2:所有模型的平均排名和95%置信区间,使用sMAPE进行排名Ensemble-DL模型的表现明显优于Ensemble-S。另外,DeepAR也取得了与Ensemble-S非常相似的结果。有趣的是,图2显示,尽管Ensemble-DL胜过Ensemble-S,但只有DeepAR胜过单个统计模型。这是为什么呢?我们将在文章的后面回答这个问题。
深度学习昂贵
深度学习模型需要大量的时间来训练(和金钱)。这是意料之中的事。结果显示在图3中:
图3:SMAPE与计算时间ln(CT)为零对应的计算时间约为1分钟,而ln(CT)为2、4、6、8和10分别对应约7分钟、1小时、7小时、2天和15天
计算上的差异是很大的。因此,降低10%的预测误差需要大约15天的额外计算时间(Ensemble-DL)。虽然这个数字看起来很大,但有一些事情需要考虑:
- 如果在集合中使用较少的模型,Ensemble-DL的计算时间可以大大减少。这显示在图4中:
之前提到,Ensemble-DL模型是200个DL模型的集合体。图4显示,75个模型可以达到与200个模型相当的精度,而计算成本只有三分之一。如果使用更巧妙的方法来做合集,这个数字还可以进一步减少。最后,本文没有探讨深度学习模型的转移学习能力。我们以后也会讨论这个问题。
集成模型
集成模型的强大是无可争议的(见图2,图3)。无论是深度学习的集成模型(Ensemble-DL)还是统计学习的集成模型(Ensemble-SL),都是表现最佳的模型。这种思想的基础是每个单独的模型都擅长捕捉不同的时间动态。将它们的预测结果结合起来能够识别复杂的模式并进行准确的推断。
短期 vs 长期
作者们研究了模型在短期预测与长期预测能力上是否存在差异。结果显示的确存在差异。图5详细展示了每个模型在每个预测视野上的准确度。例如,第1列显示了一步预测的误差。类似地,第18列显示了第18步预测的误差。
图5:1045系列的每个模型的sMAPE误差--越低越好这里有3个关键的观察:
首先,长期预测不如短期预测准确(这并不奇怪)。在前4个水平线上,统计模型获胜。除此之外,深度学习模型开始变得更好,Ensemble-DL获胜。具体来说,在第一个水平线上,Ensemble-S的准确度要高8.1%。然而,在最后一个水平线上,Ensemble-DL的准确度要高8.5%。
如果你想一想,这是有道理的:
- 统计模型是自动回归的。随着预测范围的增加,误差会不断累积。
- 相反,深度学习模型是多输出模型。因此,他们的预测误差分布在整个预测序列中。
- 唯一的DL自回归模型是DeepAR。这就是为什么DeepAR在第一个水平线上表现得非常好,与其他DL模型相反。
数据重要性
在之前的实验中,作者只使用了M3数据集中的1045个时间序列。接下来,作者使用完整的数据集(3,003个序列)重新进行了实验。他们还分析了每个水平线的预测损失。结果显示在图6中:
图6:3003系列每个模型的sMAPE误差现在,Ensemble-DL和Ensemble-S之间的差距缩小了。在第一个水平线上,统计模型与深度学习模型相匹配,但在那之后,Ensemble-DL的表现超过了它们。
让我们进一步分析Ensemble-DL和Ensemble-S之间的差异:
图7:Ensemble-DL对Ensemble-S的改进百分比随着预测步骤的增加,深度学习模型的表现超越了统计集成模型。
趋势与季节性
最后,作者们研究了统计模型和深度学习模型如何处理时间序列的重要特性,比如趋势和季节性。为了实现这一点,作者们采用了[5]的方法。具体来说,他们拟合了一个多元线性回归模型,该模型将sMAPE误差与五个关键的时间序列特性关联起来:可预测性(错误的随机性)、趋势、季节性、线性、稳定性(决定数据正态性的最佳Box-Cox参数转换)。结果如图8所示:
图8:不同指标的线性回归系数。数值越低越好我们可以观察到:
- 深度学习模型在处理噪声大、有趋势以及非线性数据方面表现更佳。
- 对于具有线性关系的季节性和低方差数据,统计模型更为合适。
这些洞察无比宝贵。因此,在为你的应用案例选择合适的模型之前,进行深入的探索性数据分析(EDA)并理解数据的本质是至关重要的。