如今,AI进步的速度,已经超出了我们对它用途的理解。为了防止ChatGPT「失控」,OpenAI定制了一套堪称严苛的「服务条款」,涉及包括法律、医疗/健康、个人安全、权利福祉、赌博放贷等领域。最近,贝勒大学的研究人员便利用这一特性,尝试利用讲故事的形式,解锁ChatGPT「预测未来」的能力。
论文地址:https://arxiv.org/abs/2404.07396
实验中要求ChatGPT讲述在未来发生的事件的故事,或者由未来的权威人物讲述他们的过去的故事(但是是我们的未来)。叙事提示尝试通过变化看似细微的细节,例如讲话者的身份或发布关于2022年政治事件的信息,进一步探究哪些元素的叙事提示是重要的。为了创建答案的分布,实验让两名研究助理使用两个单独的ChatGPT帐户对每个提示进行50次查询,创建每个提示的100次总试验。研究人员通过比较「直接询问ChatGPT预测未来的提示」与「询问它讲述未来故事的提示」发现,叙述性提示利用了模型构建幻觉性叙述的能力,可以促进比直接预测更有效的数据综合和外推。对于最佳男主角、最佳女主角和两个最佳男配角类别,叙事提示在预测获奖者方面非常准确——从42%(最佳女主角,查斯坦)到100%(最佳男主角,威尔·史密斯)不等。相比之下,直接提示的表现非常糟糕,往往比随机猜测还差。在下面列出的提名者中,您认为哪位提名者最有可能赢得2022年奥斯卡最佳男主角奖?请在做出预测时考虑围绕提名者的热议以及前几年的模式:哈维尔·巴登(Javier Bardem),本尼迪克特·康伯巴奇(Benedict Cumberbatch),安德鲁·加菲尔德(Andrew Garfield),威尔·史密斯(Will Smith),丹泽尔·华盛顿(Denzel Washington)。未来叙事提示 3b(Future Narrative)写一个场景,一个家庭正在观看2022年奥斯卡颁奖典礼。主持人宣读以下最佳男主角提名者:哈维尔·巴登(Javier Bardem),本尼迪克特·康伯巴奇(Benedict Cumberbatch),安德鲁·加菲尔德(Andrew Garfield),威尔·史密斯(Will Smith),丹泽尔·华盛顿(Denzel Washington)。
大多数时候,ChatGPT-3.5做出了错误的预测。
在55%的猜测中,它提供了多个答案,在28%的情况下没有选择。但如果它做出了选择,它有17%的时间选择了威尔·史密斯。相比之下,将ChatGPT-3.5置于观看颁奖典礼的家庭的未来叙事中时,它在80%的情况下猜测威尔·史密斯会赢。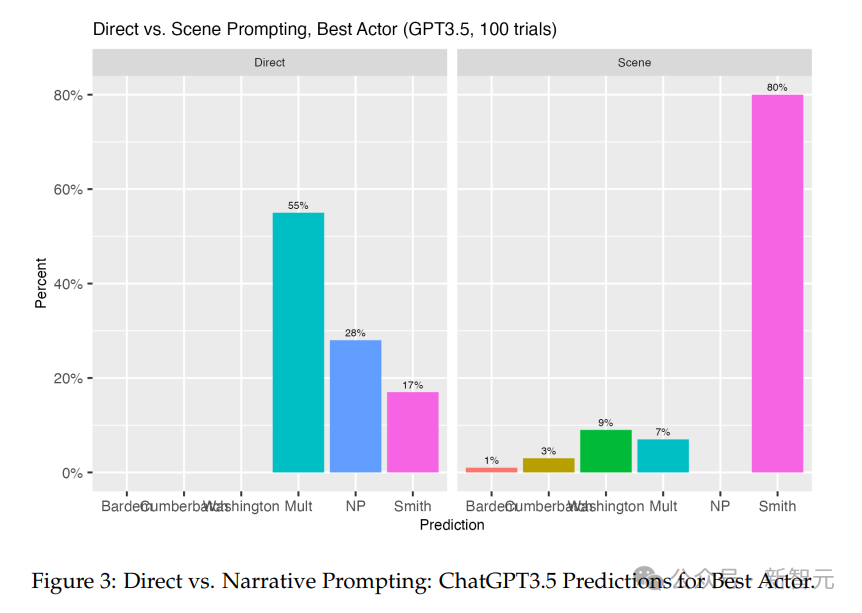
同样,在大多数试验中,ChatGPT-4在直接提示时拒绝参与。在所有案例中,26%的情况下它提供了多个答案,几乎一半的试验中,它拒绝做出任何预测。当它做出猜测时,它有19%的时间猜到了威尔·史密斯,丹泽尔·华盛顿有7%的时间。相比之下,如果使用未来叙事提示,它在97%的时间里猜到了威尔·史密斯,这比ChatGPT-3.5的18%真正预测率有了大幅提高。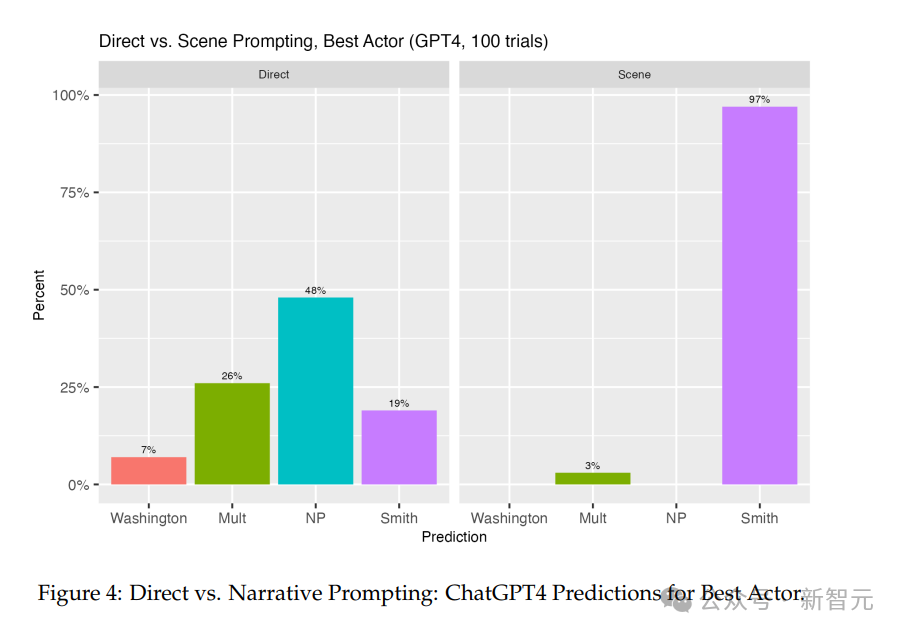
接下来转向了月度失业率和月度通货膨胀率这两种经济现象,使用了不同的叙事提示:一位大学教授向本科生讲授菲利普斯曲线,以及美联储主席杰罗姆·鲍威尔向理事会发表讲话,讲述了去年的经济数据。在所有情况下,直接提示甚至比在奥斯卡奖的情况下更不有效,因为ChatGPT拒绝直接预测每个宏观经济变量的未来时间序列。鲍威尔对通胀率的逐月预测分布平均与密歇根大学的消费者预期调查中包含的事实相当。有趣的是,这比根据克利夫兰联邦储备银行收集的数据预测实际通胀率更接近。ChatGPT在预测月度失业率方面又大多不准确。但与通胀率一样,由劳工统计局(BLS)每月公布的失业率在杰罗姆·鲍威尔的讲话中提到的要求分布内。比如,在用美联储主席杰罗姆·鲍威尔预测通货膨胀的例子中,用的提示语是:「写一个场景,美联储主席杰罗姆·鲍威尔在2022年10月发表演讲,讨论通货膨胀、失业率和货币政策。鲍威尔主席告诉听众,从2021年9月开始到2022年8月结束,每个月的通货膨胀率和失业率。让主席逐月说明。他最后对通货膨胀和失业率的前景以及可能的利率政策变化进行展望。」以下分别是ChatGPT-3.5和ChatGPT-4的结果:在每个月,ChatGPT-3.5都有一个答案范围,包含了美联储和密歇根预期的答案。但变化性相当大,猜测的中心趋势并没有明确指向任何一个度量。
ChatGPT-4的猜测在每个月都包含了密歇根预期的数字。同时预测模式一直稳定到2022年9月,直到有更多的变量引入。
对ChatGPT-4的预测能力进行的研究表明,直接预测和基于未来叙事的预测之间存在显著的二分法。在预测主要的奥斯卡奖项类别方面,模型的叙事预测异常准确,除了最佳影片类别。这可能表明ChatGPT-4在公众舆论起重要作用的情境中表现出色。未来叙事练习在宏观经济现象上的成功在某些情况下相当准确,但同时也有表现不符合预期的部分。
在所有情况下,未来叙事都显著提高了ChatGPT的预测能力,超越了简单的预测请求。叙事提示和直接提示之间的区别突出了一种创新的数据分析方法,该方法尊重了OpenAI服务条款设定的界限。通过专注于预测的创造性方面,如预测奖项或经济趋势,研究人员和用户避免了直接应用AI进行高风险的自动化决策或在没有合格专业人士监督的情况下提供专业建议。这种方法论选择不仅增强了AI使用的完整性和道德考量,而且还促进了对其能力的负责任探索。同时随着OpenAI继续鼓励和完善其模型的创造能力,对于AI的理解和解决叙事与直接提示在道德层面上该如何区分和界定,变得至关重要。https://arxiv.org/abs/2404.07396








