
向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx

NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。本文主要介绍NLTK(Natural language Toolkit)的几种语料库,以及内置模块下函数的基本操作,诸如双连词、停用词、词频统计、构造自己的语料库等等,这些都是非常实用的。
1 古腾堡语料库
http://www.gutenberg.org/

2 网络和聊天文本

3 布朗语料库
4 路透社语料库

5 就职演说语料库

运行结果:

标注文本语料库 :许多语料库都包括语言学标注、词性标注、命名实体、句法结构、语义角色等
其他语言语料库 :某些情况下使用语料库之前学习如何在python中处理字符编码
>>> nltk.corpus.cess_esp.words() ['El', 'grupo', 'estatal', 'Electricité_de_France', ...]
文本语料库常见的几种结构:
孤立的没有结构的文本集;
按文体分类成结构(布朗语料库)
分类会重叠的(路透社语料库)
语料库可以随时间变化的(就职演说语料库)
查找NLTK语料库函数help(nltk.corpus.reader)
6 载入自己的语料库

构建完成自己语料库之后,利用python NLTK内置函数都可以完成对应操作,换言之,其他语料库的方法,在自己语料库中通用,唯一的问题是,部分方法NLTK是针对英文语料的,中文语料不通用(典型的就是分词),解决方法很多,诸如你通过插件等在NLTK工具包内完成对中文的支持。
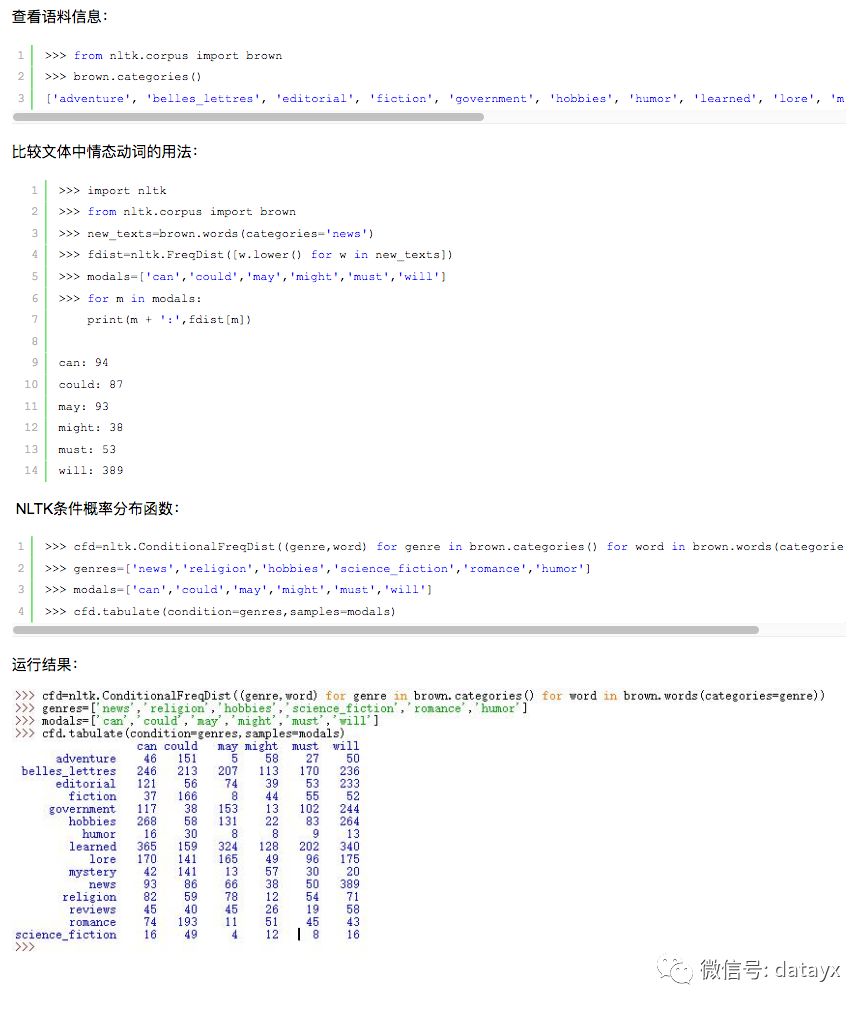
7 条件概率分布
条件频率分布是频率分布的集合,每一个频率分布有一个不同的条件,这个条件通常是文本的类别。
条件和事件:
频率分布计算观察到的事件,如文本中出现的词汇。条件频率分布需要给每个事件关联一个条件,所以不是处理一个词序列,而是处理一系列配对序列。
词序列:text=['The','Fulton','County']
配对序列:pairs=[('news','The'),('news','Fulton')]
每队形式:(条件,事件),如果我们按照文体处理整个布朗语料库,将有15个条件(一个文体一个条件)和1161192个事件(一个词一个事件)
按文体计算词汇:

运行结果:


8 更多关于python:代码重用

推荐】 古滕堡语料库
http://www.gutenberg.org/
via https://www.cnblogs.com/baiboy/p/nltk4.html
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注









