向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx
用深度学习来做自动问答的一般方法
聊天机器人本质上是一个范问答系统,既然是问答系统就离不开候选答案的选择,利用深度学习的方法可以帮助我们找到最佳的答案。
语料库的获取方法
对于一个范问答系统,一般我们从互联网上收集语料信息,比如百度、谷歌等,用这些结果构建问答对组成的语料库。然后把这些语料库分成多个部分:
训练集、开发集、测试集
问答系统训练其实是训练一个怎么在一堆答案里找到一个正确答案的模型,那么为了让样本更有效,在训练过程中我们不把所有答案都放到一个向量空间中,而是对他们做个分组,首先,我们在语料库里采集样本,收集每一个问题对应的500个答案集合,其中这500个里面有正向的样本,也会随机选一些负向样本放里面,这样就能突出这个正向样本的作用了
基于CNN的系统设计
CNN的三个优点:sparse interaction(稀疏的交互),parameter sharing(参数共享),equivalent respresentation(等价表示)。正是由于这三方面的优点,才更适合于自动问答系统中的答案选择模型的训练。
我们设计卷积公式表示如下:
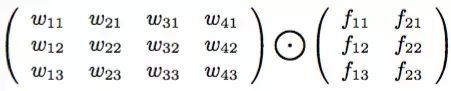
假设每个词用三维向量表示,左边是4个词,右边是卷积矩阵,那么得到输出为:
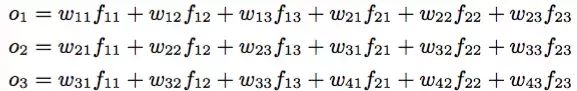
如果基于这个结果做1-MaxPool池化,那么就取o中的最大值
通用的训练方法
训练时获取问题的词向量Vq(这里面词向量可以使用google的word2vec来训练,和一个正向答案的词向量Va+,和一个负向答案的词向量Va-, 然后比较问题和这两个答案的相似度,两个相似度的差值如果大于一个阈值m就用来更新模型参数,然后继续在候选池里选答案,小于m就不更新模型,即优化函数为:
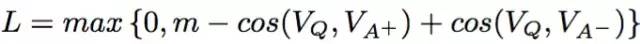
参数更新方式和其他卷积神经网络方式相同,都是梯度下降、链式求导
对于测试数据,计算问题和候选答案的cos距离,相似度最大的那个就是正确答案的预测
神经网络结构设计
以下是六种结构设计,解释一下,其中HL表示hide layer隐藏层,它的激活函数设计成z = tanh(Wx+B),CNN是卷积层,P是池化层,池化步长为1,T是tanh层,P+T的输出是向量表示,最终的输出是两个向量的cos相似度
图中HL或CNN连起来的表示他们共享相同的权重。CNN的输出是几维的取决于做多少个卷积特征,如果有4个卷积,那么结果就是4*3的矩阵(这里面的3在下一步被池化后就变成1维了)


以上结构的效果在论文《Applying Deep Learning To Answer Selection- A Study And An Open Task》中有详细说明。
要把深度学习运用到聊天机器人中,关键在于以下几点:
对几种神经网络结构的选择、组合、优化
因为是有关自然语言处理,所以少不了能让机器识别的词向量
当涉及到相似或匹配关系时要考虑相似度计算,典型的方法是cos距离
如果需求涉及到文本序列的全局信息就用CNN或LSTM
当精度不高时可以加层
当计算量过大时别忘了参数共享和池化
最初接到导师给的研究题目(自动问答)是在2017年4月上旬,然后就在看大牛们写论文(文末给地址),找相关资料以及研究市场上各种现有的商业自动问答产品中度过了一个月,这个过程中少不了狂和机器人聊天,测试不同产品对同类问题的反应。
Eric有哪些功能?
使用方法
测试环境为windows7 + Python2.7(Anaconda2) 需要额外安装的Python包有:
下载整个工程,直接运行QA-Snake/QA/MainProgram.py
或者 打开dist目录,下载 并安装 QASnake-0.1.0.tar.gz
pip install QASnake-0.1.0.tar.gz
新建一个.py文件
import QA.qa as qa
if __name__ == '__main__':
qa.qa()
目前只支持命令行模式和Socket模式,后期会提供更多的接口。
现代的自动问答是将自然语言处理、统计机器学习深度学习相结合的产物。自从1950年代图灵测试而诞生至今,自动问答系统的发展已经有几十年的历史。但真正在产业界得到大家的广泛关注,则得益于2011年Siri和Watson的成功。这一方面归功于机器学习与自然语言处理技术的快速进步,另一方面得益于维基百科等大规模知识库以及海量网络信息,也就是大数据的飞速发展。
然而,现有的自动问答系统还不够完美,部分还是基于关键字模版匹配(包括一些商业产品),无法真正做到语义理解的程度。在通用领域实现一个不被大多数人喷的问答系统更是难上加难。事实上,无论是业界应用还是学术研究,问句的真实意图分析、问句与答案之间的匹配关系判别仍然是制约自动问答系统性能的两个关键难题。
几乎所有的问答系统的流程可以归结为以下几部分:
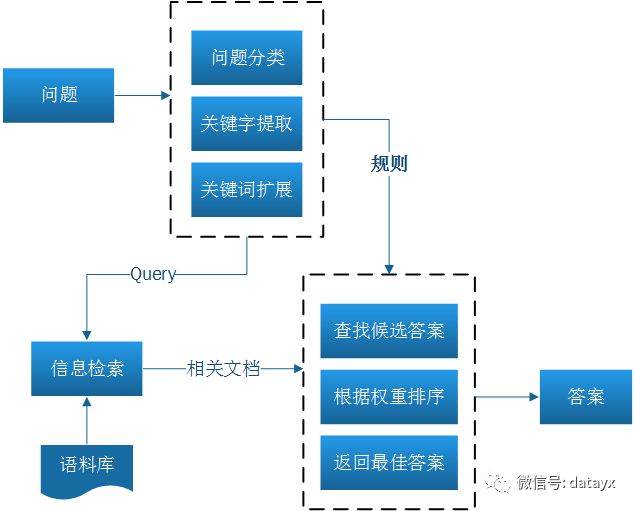
目前的研究工作大多集中于上图的两个虚线框中的内容,有用传统的规则搞的,也有用统计方法搞的,也有用深度学习方法搞的。中文的问答系统,还需要进行分词等工作。问答系统又不同于聊天机器人(小冰等),它是要解决实际问题的。比如客服问答机器人,阿里和京东的都做得非常不错,这不仅是基于他们强大的研发团队,足够的数据支撑模型训练也是重要的因素之一。
然而,我就想做个简单的问答机器人,然后顺利毕业啊。没有那么多公开的中文数据,怎么破?学术界的大多方法还不能很好地运用到工业界。看完论文和大多商业产品后,我开始思考Eric的定位,由于目前中文的问答训练集非常少,并且没有通用的问答训练集,这对于一开始想采用统计机器学习、深度学习训练一个问答模型的我造成了非常大的困难,这个问题足足困扰了我一周。在不断查找资料的过程中我发现了AIML,非常棒的人工智能标记语言。Alice是一个基于AIML实现关键词匹配和简单的推理的聊天机器人,它的语料库非常之大,不过是英语的。
但不管怎么样这是一种实现问答机器人的方式,于是我先跑通了基于AIML的问答机器人。但是他仅仅是基于关键词匹配和简单的推理,缺少语义理解的能力,虽然它的可扩展性非常强,但是如果只做到这步的话,我想我是没办法顺利毕业了。
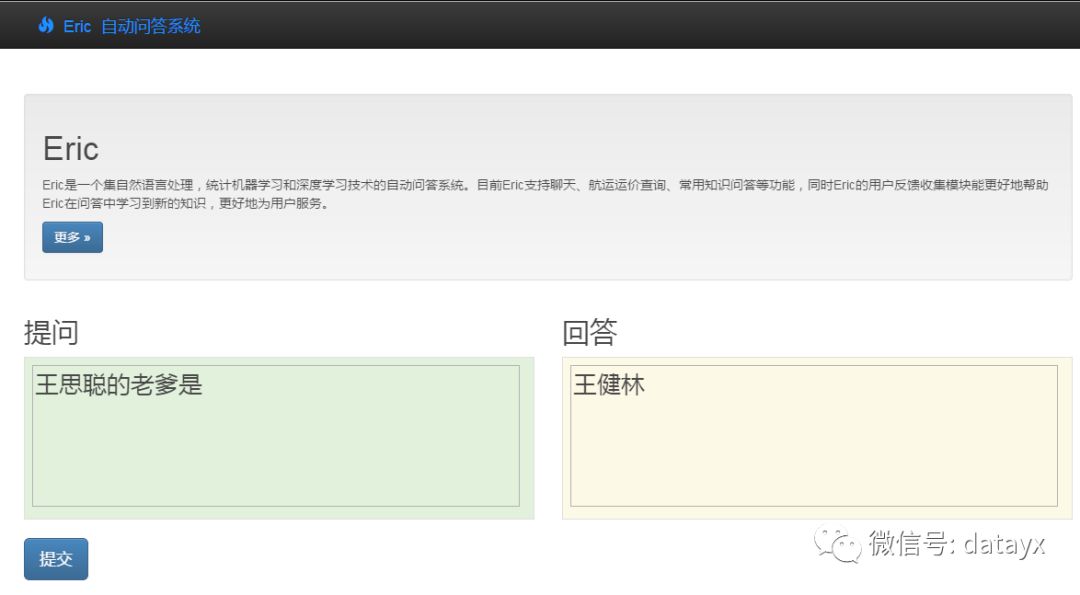
在研究AIML的过程中,我发现了互联网上有许多半结构化数据。比如维基百科,百度百科等。我尝试使用AIML把问句转换成一种结构化的Query,然后再百度百科中找到对应属性的属性值。比如“王思聪的父亲是谁?”这个问题,AIML根据规则会抽取出“王思聪”,“父亲”。抽取出来的实体和属性是很容易在百度百科中搜索到的。但问题又来了,如果问“王思聪的老爹是?”这类问题,Eric就找不到答案了。为了解决这个问题,我引入了哈工大的同义词词林进行关键词扩展。
做到这步,基本上百度百科上有的答案我都能搜出来了。但是这还远远不够,对于百度百科没有的答案怎么办呢?有些问题的答案其实已经在搜索引擎的前几十条答案中有,人很容易找出这些答案,但机器怎么找答案呢?
知识图谱是我原本想模仿百度百科做的一个本地知识库,后来发现,要构建这样的通用知识库太麻烦了,工作量非常之大。那么既然百度有了知识图谱,我为何不去尝试用它,而要重复造轮子呢?同样的道理,本地其实不需要太多的知识,所有的知识搜索引擎几乎都能找到,为何还要耗时费力的去构建本地的知识库呢,我的知识库就是整个互联网啊。百度没有搜到的东西,Bing有吧,Google有吧?
做到这步Eric的定位就比较清晰了,自动问答的问题也就变成了根据问句从互联网中抽取答案。我还想做闲聊,但是也没训练集。我尝试让两个产品的机器人互聊,借此收集语料,结果他们聊死了。最后在网上找到一个质量一般的聊天对话语料库,暂时凑合着先用。后面有时间再来聊优化闲聊的部分。
我采用BeautifulSoup对百度知道、百度百科、百度搜索、Bing搜索这四个信息源进行了规则解析。这里要提一下百度知道(包括类似的问答社区),在线搜索解析的成本真的比写爬虫把数据抓取并存储成结构化知识要省力得多,现成的知识库要灵活运用起来。
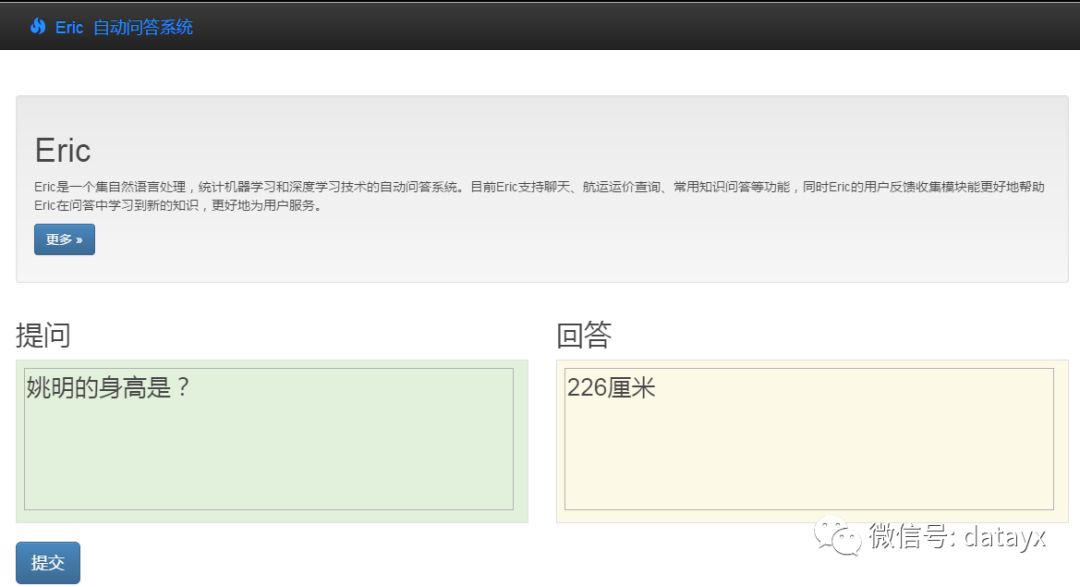
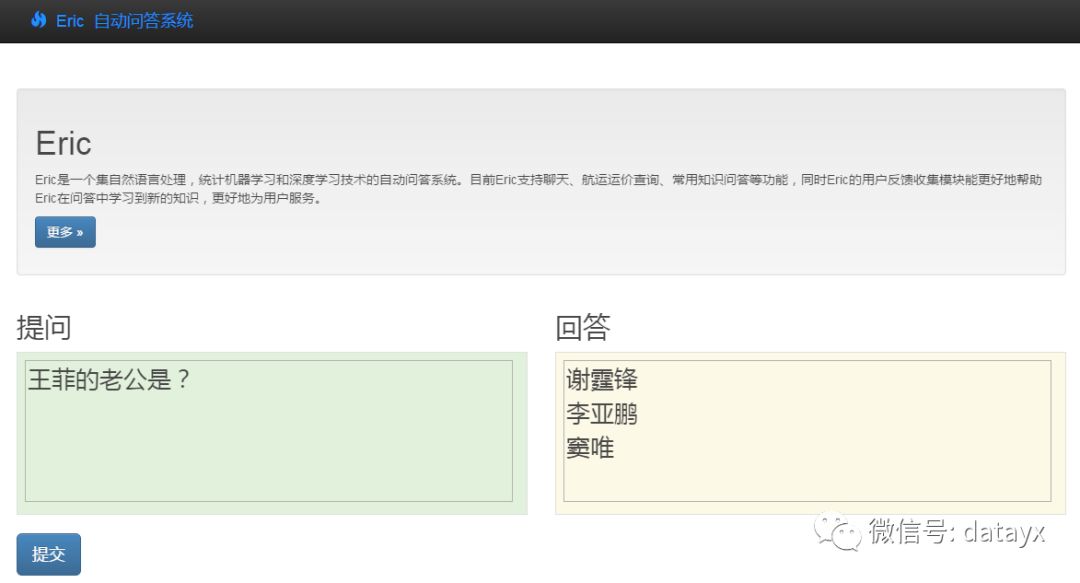
下面是Eric的问句效果,我拿杨尚川老师的“测试人机问答系统智能性的3760个问题”以及自己收集的问题进行了测试,结果还凑合。下面是结果,用Django简单写了个站进行展示:

Github上放出来的代码提供了支持命令行的问答模块以及基于Socket通信的server端,代码很乱,后续会做进一步改进。
代码获取:
关注微信公众号 datayx 然后回复 自动问答 即可获取。
总结:
目前的Eric还很稚嫩,还存在包括但不仅限以下问题:
1.多轮对话能力为零
2.回答没有情感
3.对于搜索引擎都找不到的答案,没有自己的“思维”抽象能力。
4.问答的结果如何评估?目前都是人在看,对于中文的问答有没有比较好的评估标准和方式?
5.语义相同问法不同的问句返回的答案会不一致,还是没做到语义理解。
后期我将做以下工作:
1.将CNN问句分类用于Eric,为后续对不同类别的问句做针对性回答策略做铺垫。(目前遇到的问题还是训练集不够,模型用Tensorflow已经搭好了。)
2.尝试解决语义理解。
3.问句收集模块的设计与实现。
4.对于多个候选答案进行打分排序,提出一个打分策略并验证可行性。
via http://www.snakehacker.me/411
阅读过本文的人还看了以下:
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
常见面试算法:树回归、树剪枝
常见面试算法:朴素贝叶斯
常见面试算法:支持向量机
常见面试算法:PCA、简化数据
常见面试算法:Logistic回归、树回归
常见面试算法:回归、岭回归、局部加权回归
常见面试算法:决策树、随机森林和AdaBoost
常见面试算法:k-近邻算法原理与python案例实现
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
深度学习 500问
超参数:比如算法中的 learning rate (学习率)、iterations(梯度下降法循环的数量)、(隐藏
层数目)、(隐藏层单元数目)、choice of activation function(激活函数的选择)都需要根据实际
情况来设置,这些数字实际上控制了最后的参数和的值,所以它们被称作超参数。
某一个任务,某个具体的分类器不可能同时满足或提高所有上面介绍的指标。