
向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx
本文是 Andrew NG 《Machine Learning Yearning》 的「第九章:端到端的深度学习」翻译。Andrew NG
提到他曾经负责开发过一个大型端到端语音识别系统,并取得的很好的效果,但是他同时表示盲目使用该技术并不是好事。本章内容将探讨什么是端到端的深度学习?
什么时候应该使用它,什么时候应该避免它?同时给出了当不适合使用端到端学习技术之时,如何将机器学习任务分解成多个子任务的建议。
端到端学习技术的兴起
假设你希望构建一个系统来检索关于在线购物网站上的产品评论,并自动通知你,用户是否喜欢或不喜欢该产品。例如,你希望识别出以下评论是属于积极评论:
识别出以下评论是属于消极评论:
识别正面和负面意见的机器学习问题被称为「情感分类」问题。为了建立这个系统,你可以构建一个由两部分组成的「管道(Pipeline)」:
解析器(Parser):一种用来标注文本内容中最重要的单词信息1的系统,例如,你可以使用解析器来标记文本中所有的形容词和名词,因此例子变成了下列所示的那样:
This is agreatAdjectve mopNoun
情感分类器(Sentiment
classifier):一种将带注释的文本作为输入,并预测整体情绪的学习算法。解析器的注释可以极大地帮助这个学习算法:通过给予形容词一个更高的权重,你的算法将能够快速地识别出那些重要的单词(如「great」),同时忽略不那么重要的单词,例如「this」。
我们将两个组件组成的「管道」可视化如下:
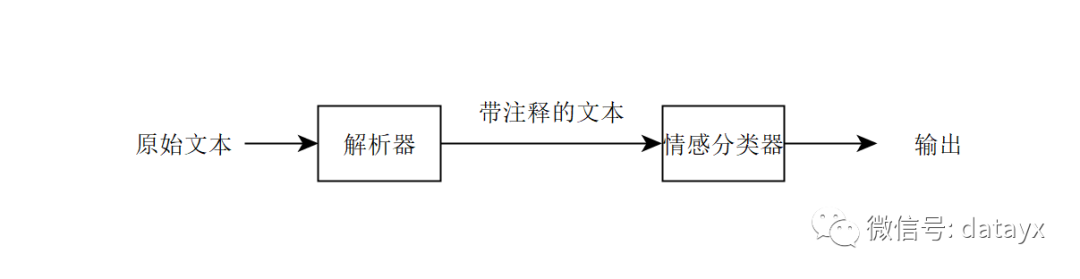
近期出现了用单一学习算法替代管道系统的趋势。这项任务的端到端学习算法尝试在仅输入原始文本「This is a great mop!」的情况下直接识别情绪的可能性:

神经网络通常用于端到端学习系统。术语「端到端(End-to-end)」指的是我们要求学习算法直接从输入到所需的输出。即,学习算法直接将系统的「输入端」连接到「输出端」。
在处理一些数据丰富的应用中,端到端学习算法非常成功。但这并不意味着它们总是一个好的选择。接下来的几章将给出更多的端到端系统的例子,并给出关于何时应该使用它们和不应该使用它们的建议。
更多的端到端学习的例子
假设你想建立一个语音识别系统。那么你可以构建一个包含三个组件的系统:
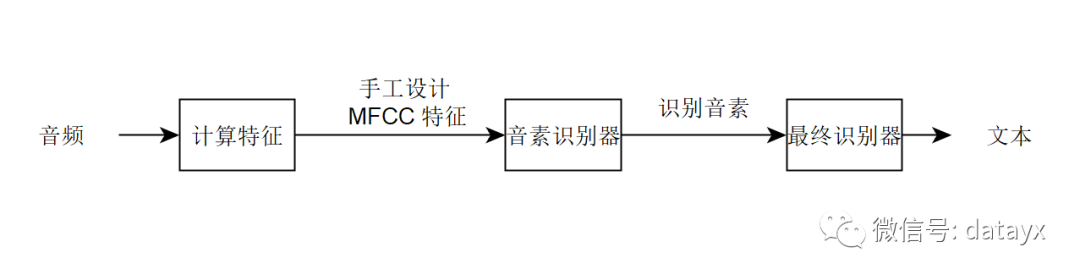
这些组件的职能如下:
计算特征:提取手工设计的特征,例如 MFCC 特征(梅尔频率倒谱系数),它尝试捕捉话语的内容,同时忽略不太相关的属性,例如说话者的音调;
音素识别器:一些语言学家认为声音的基本单位是「音素」。例如,「keep」中最初的「k」音与「cake」中的「c」音相同。这个识别器试图识别音频片段中的音素;
最终识别器:取出识别的音素序列,并尝试将它们串成一个输出抄本。
相反,端到端的系统可能会输入一个音频剪辑,并尝试直接输出文本:

到目前为止,我们只描述了完全线性的机器学习「管道」——输出顺序从一个阶段传递到下一个阶段。然而,管道可能更复杂,例如,这里有一个自动驾驶汽车的简单架构:
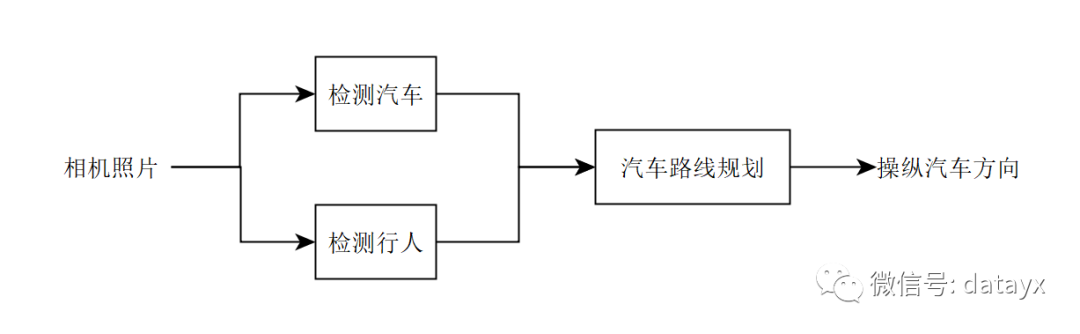
它有三个组成部分:一个负责使用相机图像检测其他车辆; 一个负责检测行人; 最终的组件则为我们的汽车出规划一条避开汽车和行人的道路来。
然而,并不是说管道中的每个组件都需要训练和学习。例如,有关「机器人运动规划」的文献中就有大量关于汽车最终路径规划步骤的算法。这里边的许多算法都不涉及学习。
相反,端到端的方法可能尝试接受传感器输入并直接输出转向方向。
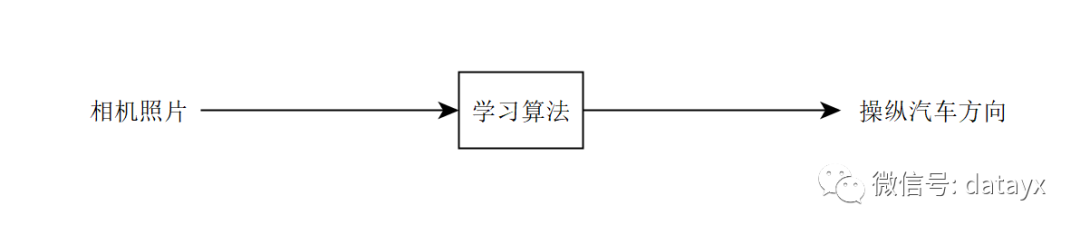
尽管端到端学习已经取得了许多成功,但它并不总是最好的方法。例如,我们认为端到端的语音识别效果很好,但对自主驾驶的端到端学习则持怀疑态度。接下来的几章我会解释原因。
端到端学习的优点和缺点
考虑与我们之前的例子相同的语音系统管道:
这条管道的许多部分都是「手工设计的」:
虽然这些手工设计的组件限制了语音系统的潜在性能。但是,允许手工设计的组件也有一些优点:
拥有更多手工设计的组件通常可以让语音系统以更少的数据进行学习。MFCCs 和基于音素捕获的手工工程知识「补充」了我们的算法从数据中获得的知识。当我们没有太多的数据时,这些知识是有用的。
现在,考虑端到端系统:
该系统缺乏手工设计的知识。因此,当训练集很小时,它可能比手工设计的管道更糟糕。
然而,当训练集很大时,它不会受到 MFCC 或基于音素表示的限制。如果学习算法是一个足够大的神经网络,同时经过了足够多的训练数据的训练,那么它就有可能做得很好,甚至可能接近最优错误率。
当有大量的「两端」(输入端和输出端)标记数据时,端到端学习系统往往会做得很好。在本例中,我们需要一个大数据集(音频-文本对)。因此,当这种类型的数据不可用时,请小心谨慎地进行端到端的学习。
如果你正在研究一个机器学习问题,而训练集非常小,那么你的算法的大部分知识都必须来自于你的人类洞察力——即,来自你的「手工工程」组件。
如果你选择不使用端到端系统,那么你必须决定管道中的每一个步骤,以及它们连接次序。在接下来的几章中,我们将对此类管道的设计提出一些建议。
选择管道组件:数据可用性
在构建非端到端学习的管道系统时,管道组件的最佳选择是什么?如何设计管道将极大地影响整个系统的性能,其中一个重要因素是你是否可以轻松收集数据来训练管道的每个组件。
例如,下列这个自动驾驶汽车的算法架构:
你可以使用机器学习算法来检测汽车和行人。此外,获取这些数据并不困难:有许多计算机视觉数据集——大量标记了汽车和行人。你还可以使用众包(比如Amazon
Mechanical Turk)来获取更大的数据集。因此,对于训练自动驾驶算法的汽车和行人检测器来说,训练数据的获取相对容易。
相反,考虑一种纯粹的端到端方法:
为了训练这个系统,我们需要一个大的(图像,方向)对数据集。让人们驾驶汽车并记录他们的转向方向来收集这些数据是非常耗时和昂贵的。同时你需要一支特别装备的车队,以及通过大量的驾驶来尽可能的覆盖所有可能遇到的场景,这使得端到端的学习系统很难训练。相比而言,获得大量的有标记的汽车或行人图像的数据集要容易得多。
更一般地说,如果有许多数据可用来训练管道的「中间模块」(例如,汽车检测器或者行人检测器),那么你可以考虑使用具有多个阶段的管道。这种结构可能更优越,因为你可以使用所有可用数据来训练中间模块。
在更多的端到端数据可用之前,我认为非端到端方法对于自动驾驶来说更有希望:它的架构能够更好地发挥出数据的价值来。
选择管道组件:任务简单性
除了数据可用性之外,在选择管道组件时还应考虑第二个因素:单个组件需要解决的任务有多简单? 您应该尽可能尝试选择那些易于构建或学习的管道组件。那么,对于一个管道组件来说,何谓之「易于」学习呢?
思考下列的机器学习任务,并按照从难到易的顺序依次列出:
分类图像是否曝光过度(如上例所示);
分类图像是室内还是室外拍摄;
分类图像是否包含猫;
分类图像是否包含黑色和白色毛皮的猫;
分类图像是否包含暹罗猫(特定品种的猫)。
上述任务每一个都是属于图像的二分类任务:输入图片,输出 0 或者 1。但是列表前面的知识似乎更容易让神经网络学习到。也即是说,用更少的样本训练更简单的任务。
到目前,机器学习还没有一个好的正式定义来定义是什么导致了一项任务变得容易或困难2。但随着深度学习和多层神经网络的兴起,我们有时候会将那些只需要较少的计算步骤就能完成的任务定义为「容易」(对应于浅层神经网络)。而将那些需要更多的计算步骤才能完成的任务定义为「困难」(对应于深层神经网络)。但这都是非正式定义。
如果您能够将一个复杂的任务,将其分解为更简单的子任务,那么通过显式地对子任务的步骤进行编码,你就给了算法先验知识,这可以帮助它更有效地学习一项任务。

假设您正在构建一个暹罗猫检测器。 下列是一个纯粹的端到端学习架构:

相比之下,您可以选择使用管道,步骤有两个:

第一步(猫检测器)检测图像中的所有猫:
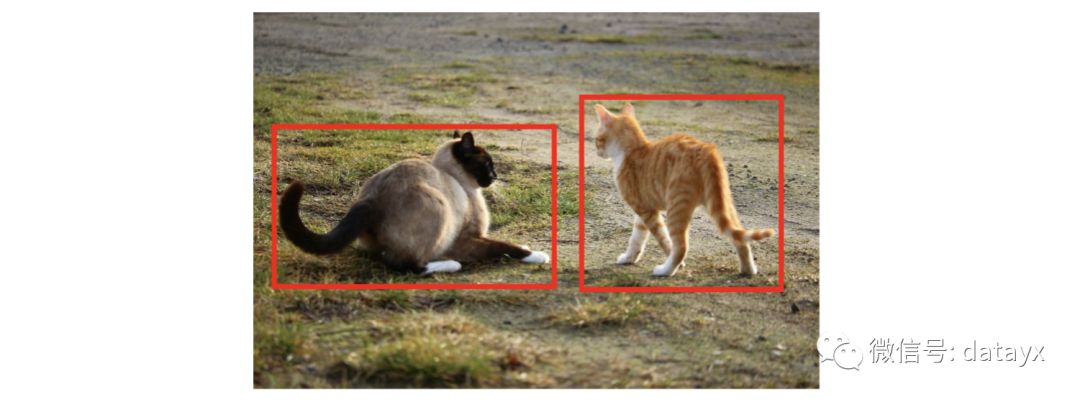
然后,第二步将每个检测到的猫(一次一个)的裁剪图像传递给猫品种分类器,如果检测到的猫分类为是暹罗猫,则输出 1。
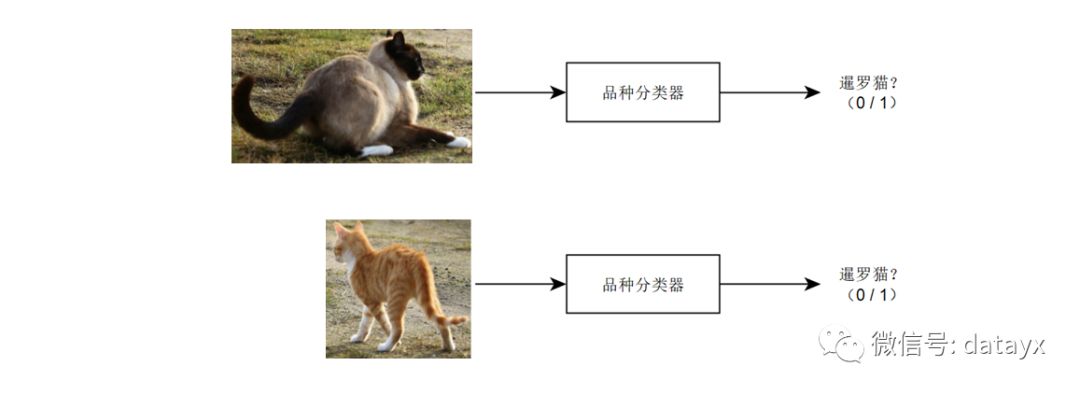
与使用标签 0/1 训练纯粹的端到端分类器相比,管道中的两个组件中的每一个——猫探测器和猫品种分类器——似乎都更容易学习,并且只需要更少的数据
作为最后一个例子,让我们重新回顾之前的自动驾驶算法管道:
通过使用这条管道,你可以告诉算法有 3 个关键步骤:(1)检测其他车辆;(2)检测行人;(3)为你的汽车规划道路。此外,与纯粹的端到端学习方法相比,这些方法都是一个相对简单的函数,因此可以用更少的数据来学习。
总之,在决定管道组件应该是什么时,尝试去构建一个管道,让其中每个组件都是一个相对「简单」的功能,从而让组件能够使用较少的数据进行学习。
直接学习复杂的输出
图像分类算法输入图像 x" role="presentation">x
,输出一个表示对象类别的整数。那么,算法可以输出描述图像的句子吗?
比如:

传统的监督学习算法学习函数 h" role="presentation">h
:X→Y" role="presentation">X→Y,其中输出 y" role="presentation">y
通常是整数或者实数。例如:
| 应用场景 | X | Y |
|---|
| 垃圾邮件分类 | 邮件 | 垃圾邮件/不是垃圾邮件(0/1) |
| 图像识别 | 图片 | 整数标签 |
| 房子价格预测 | 房子的特征 | 房子价格 |
| 产品推荐 | 商品或者用户特征 | 购买的机会 |
端到端的深度学习中最令人兴奋的发展之一是它可以让我们直接学习到比数字复杂得多的 y" role="presentation">y
。在上面的图像字幕示例中,可以让神经网络输入图像 x" role="presentation">x 并直接输出标题 y" role="presentation">y
更多的例子:
| 应用场景 | X | Y | 例子引用 |
|---|
| 图像字幕 | 图片 | 文字 | Mao et al., 2014 |
| 机器翻译 | 英文文本 | 法文文本 | Suskever et al., 2014 |
| 问答系统 | 问题文本 | 答案文本 | Bordes et al., 2015 |
| 语音识别 | 音频 | 转录文本 | Hannun et al., 2015 |
| 文本转语音 | 文本特征 | 音频 | van der Oord et al., 2016 |
这是深度学习中的一个趋势:当你有正确的(输入、输出)标记对时,你就可以尝试去使用端到端学习技术,即使输出是一个句子、一个图像、音频或其他比单个数字更丰富的输出。
解析器给出的文本注释要比这个丰富得多,但是这个简化的描述足以解释端到端的深度学习
信息论中有一个概念叫做:「柯尔莫哥洛夫复杂性(Kolmogorov Complexity)」——学习函数的复杂性等价于可以产生该函数的最短计算机程序的长度。然而,这一理论概念在人工智能中几乎没有实际应用。详见:https://en.wikipedia.org/wiki/Kolmogorov_complexity
如果你熟悉对象物体检测算法,那么你应该知道它们不仅仅只学习 0/1 图像标签,而是使用作为训练数据的一部分提供的边界框进行训练。对他们的讨论超出了本书的范围,详见 Coursera (http://deeplearning.ai),有相关课程专门讨论对象物体检测。
https://alberthg.github.io/2018/06/27/machine-learning-yearning-c9/









