
作者:Parul Pandey
翻译:吴慧聪
校对:吴振东
本文约2600字,建议阅读8分钟。
本文将介绍10个Jupyter Notebook中进行数据挖掘的提速小技巧。

简介
提示和技巧总是非常有用的,在编程领域更是如此。有时候,小小的黑科技可以节省你大量的时间和精力。一个小的快捷方式或附加组件有时会是天赐之物,可以成为实用的效率助推器。所以,我在这里介绍下自己编程时最喜欢使用的一些提示和技巧,在这篇文章中汇总起来呈现给大家。有些可能是大家熟悉的,而有些可能是新鲜的,我相信它们会为你下一次处理数据分析的项目时提供便利。
1. 预览Pandas中的数据框数据(Dataframe)
分析预览(profiling)是一个帮助我们理解数据的过程,在Python中Pandas Profiling 是可以完成这个任务的一个工具包,它可以简单快速地对Pandas 数据框进行搜索性数据分析。Pandas中df.describe()和df.info()函数通常可以实现EDA过程的第一步,但如果只是给出非常基础的数据预览并不能对分析那些大型的数据集提供帮助。另一方面来看,Pandas Profiling函数能通过一行代码来展示出大量的信息,而在交互式HTML报告中也是这样。
对于一个给定的数据集,Pandas Profiling 工具包将会计算出下面的统计信息:

由pandas profiling包算出的统计信息
代码示例:
Python2.x的版本中,运用pip或conda安装pandas-profiling资源包:
pip install pandas-profilingorconda install -c anaconda pandas-profiling
现在用一个古老的泰坦尼克数据集来演示多功能python profiler的结果:
#importing the necessary packagesimport pandas as pd import pandas_profiling df = pd.read_csv('titanic/train.csv') pandas_profiling.ProfileReport(df)
这一行就是你需要在jupyter notebook中形成数据分析报告所需的全部代码。这个数据报告十分详细,包括了所有必要的图表。
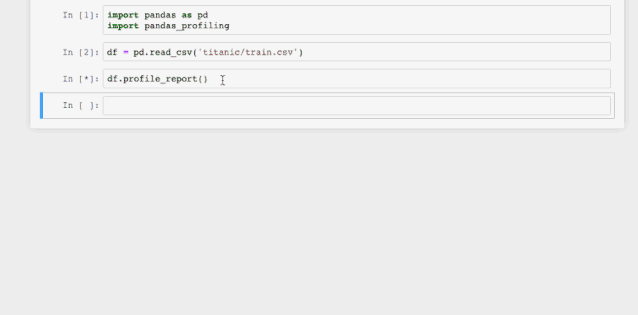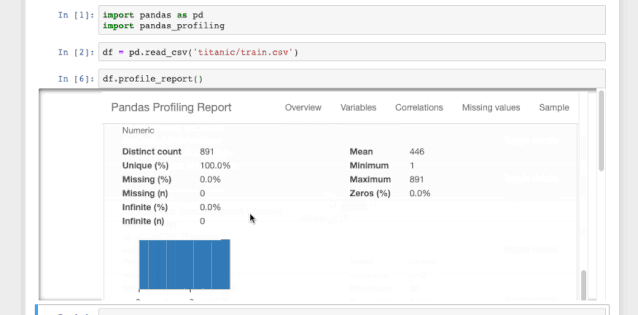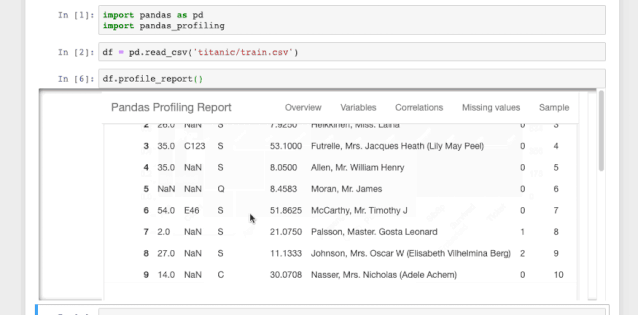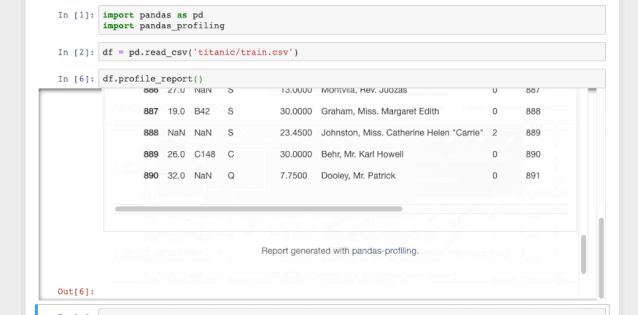
图1.1
这个报告也可以用下面的代码形成交互HTML文件(interactive HTML file)导出:
profile = pandas_profiling.ProfileReport(df)profile.to_file(outputfile="Titanic data profiling.html")
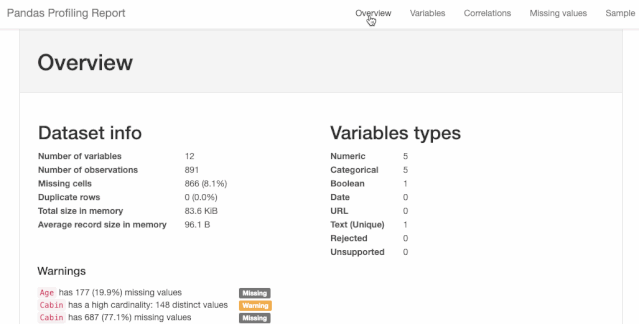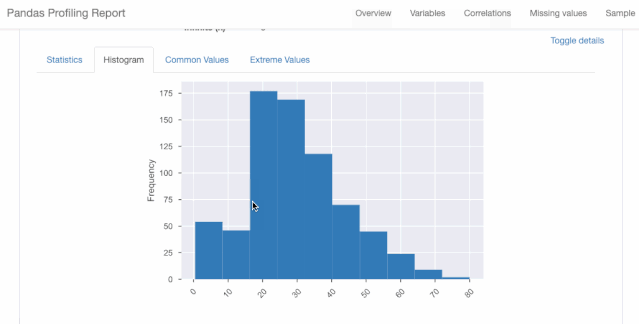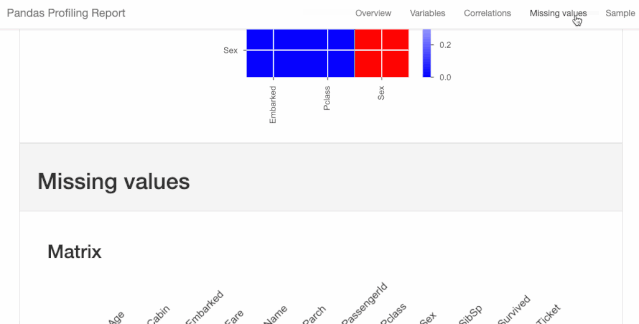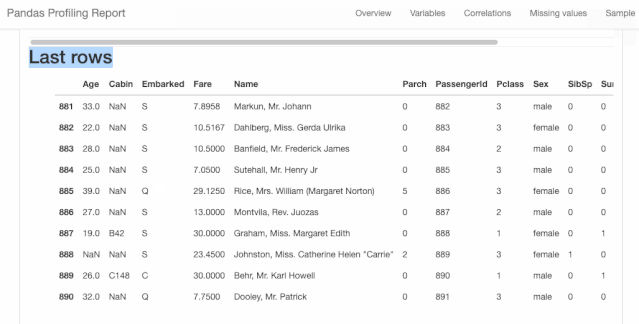
图1.2
2. Pandas图表(Plot)的交互性
Pandas中有一个内置的.plot()函数作为数据框(Dataframe)的一部分,但因为这个函数呈现的可视化并不是交互的,这使它的功能没那么吸引人。而且,使用pandas.DataFrame.plot()函数绘制图表也并不容易。如果我们想要在没有对代码进行重大修改的情况下用pandas绘制交互式图表要怎么办?嗯,可以通过Cufflinks资源包来帮助你完成这一目的。
Cufflinks资源包将功能强大的plotly和灵活易用的pandas结合,非常便于绘图。现在我们来看看怎么安装和在pandas中使用这个资源包。
代码示例:
Python2.x的版本中,使用pip安装plotly和cufflink:
pip install plotly pip install cufflinks
调用方法:
import pandas as pd import cufflinks as cf import plotly.offlinecf.go_offline() cf.set_config_file(offline=False, world_readable=True)
下面来看一下泰坦尼克数据集所展现的魔力:
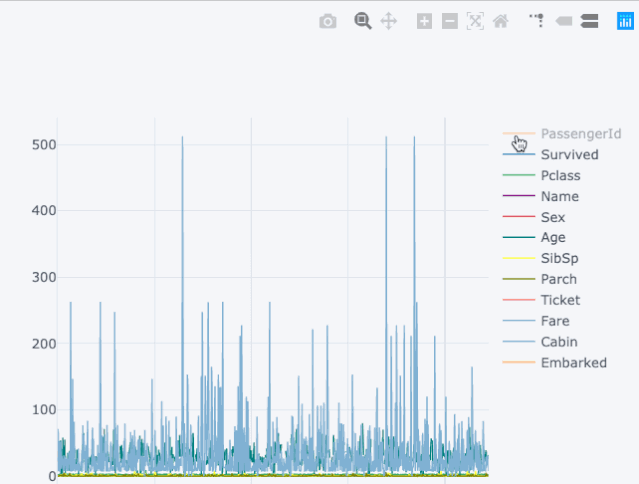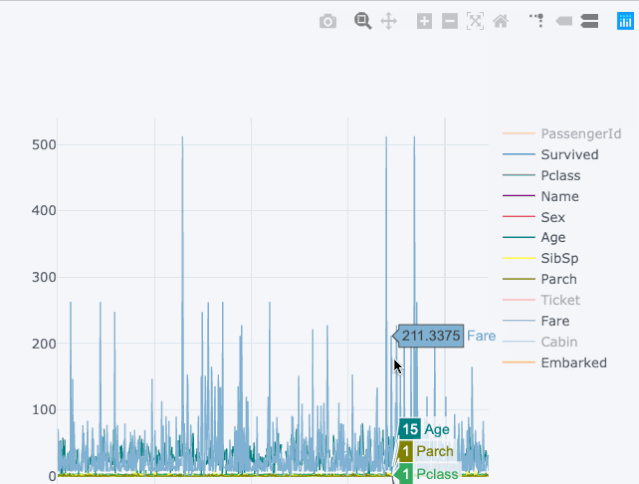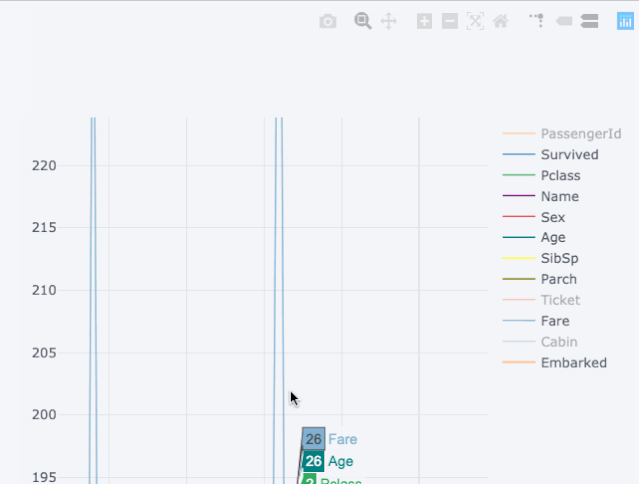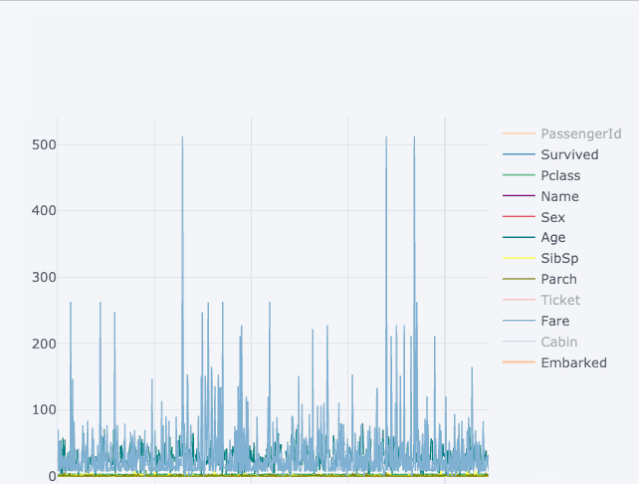
图2.1
图2.2
右边的可视化展示的是静态的线状图,而左边的图是交互式的,并且更加详细,两个图在代码上没有重大的变化。
Github的链接中将会有更多的示例:
https://github.com/santosjorge/cufflinks/blob/master/Cufflinks%20Tutorial%20-%20Pandas%20Like.ipynb
3. 一点点魔法
Magic命令是Jupyter Notebook中的一组便捷功能,它们旨在解决数据分析中一些常见的问题。你可以用%Ismagic来查阅所有的Magic 命令。
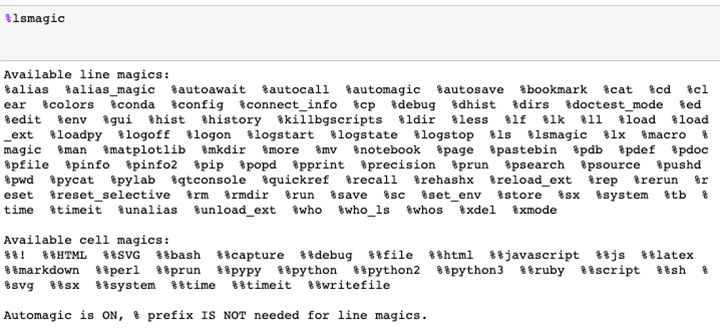
上图列举了所有可用的Magic 函数
Magic命令有两大类:行magic命令(line magics),以单个% 字符为前缀,单行输入操作;单元magics命令(cell magics),以双%% 字符作为前缀,可以在多行输入操作。如果设置为1,我们使用magic 函数时不需要键入%。
下面让我们来看一下,在常见的数据分析任务中一些可能会用到的命令。
% pastebin将代码上传到Pastebin并返回一个链接。Pastebin是一个线上内容托管服务,我们可以在上面存储纯文本,如源代码片段,所形成的链接也可以分享给他人。事实上,Github gist也类似于pastebin,只是它带有版本控制。
代码示例:
来看一下这个file.py的python代码文件中的内容:
#file.pydef foo(x): return x
在Jupyter Notebook中使用% pastebin形成一个pastebin的链接。
%matplotlib inline函数用于在Jupyter笔记本中呈现静态matplotlib图。我们可以尝试用notebook来代替inline得到可轻松地缩放和调整大小的绘图,但要确保在套用matplotlib资源包之前调用该函数。
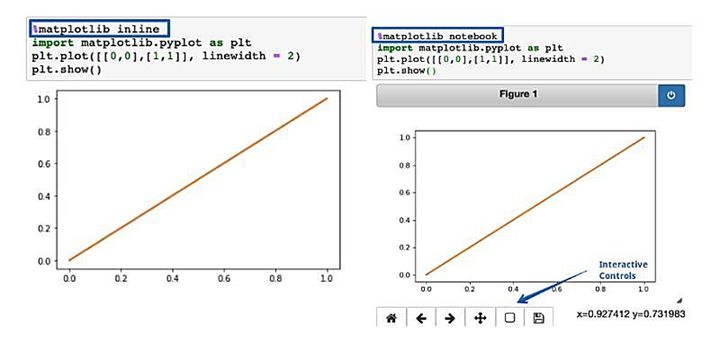
%matplotlib inline vs %matplotlib notebook
%run函数用于jupyter notebook中运行一个python脚本文件。
%% writefile将执行单元的内容写入文件。下面的这段代码将写入名为foo.py的文件并保存在当前目录中。

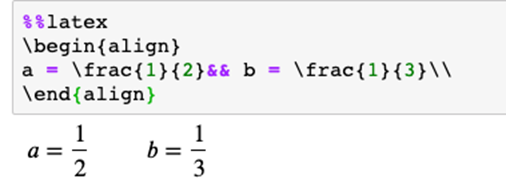
%% latex函数将单元格内容以LaTeX的形式呈现。它对于在单元格中编写数学公式和方程很有用。
4. 发现并减少错误
交互式调试器(interactive debugger)也是一个Magic函数,但我必须给它归个类。如果你在运行代码单元出现异常时,可以在新行中键入%debug运行。这将打开一个交互式调试环境,它将您告诉你代码发生异常的位置。你还可以检查程序中分配的变量值,并在此处执行操作。点击q可退出调试器。
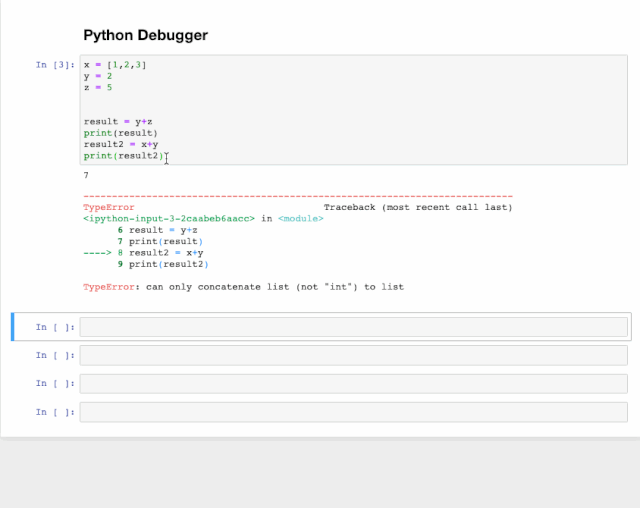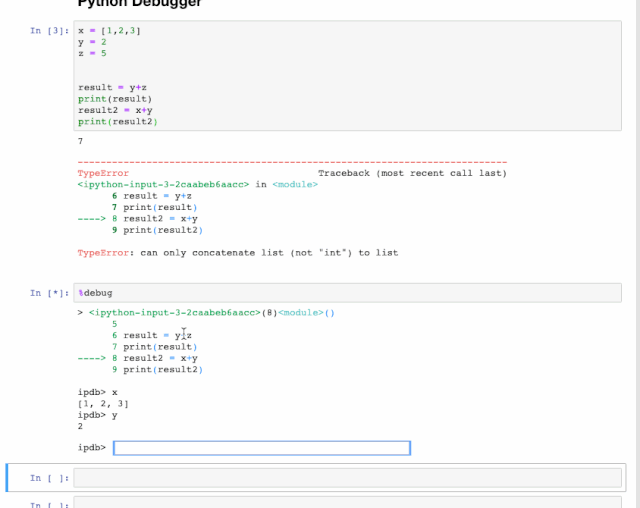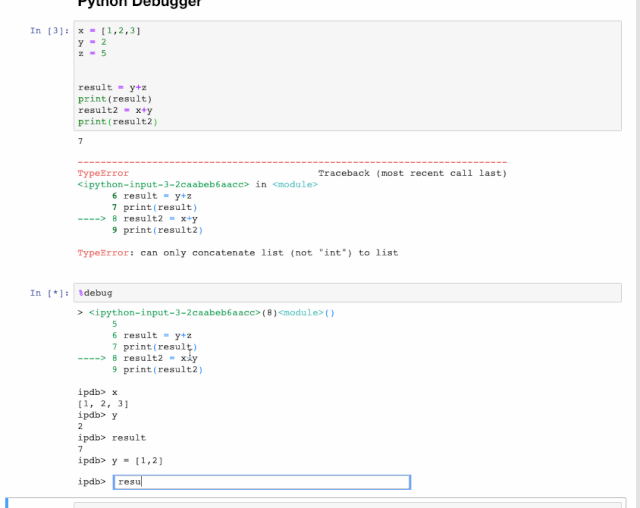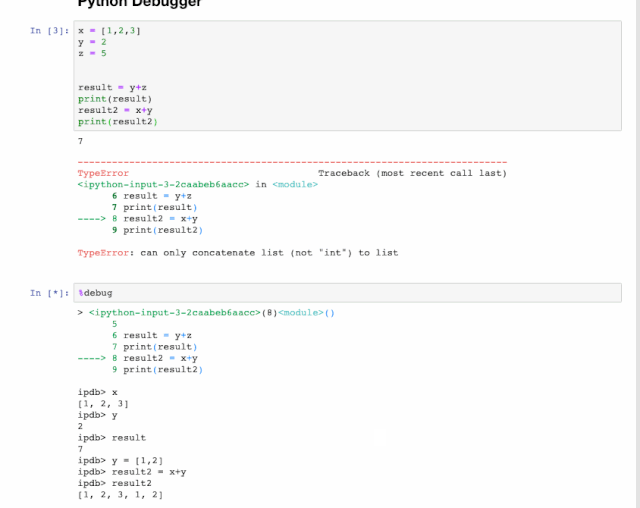
5. 输出也可如此美观
如果你想生成美观的数据结构,pprint是首选的模块。它在输出字典数据或JSON数据时特别有用。下面来看一下print 和pprint输出的一个例子:


6. 让提示更突出
可以在你的Jupyter Notebook中使用提示/注释框来突出显示任何重要的内容。注释的颜色取决于指定的提示类型。只需在代码中加入需要突出显示的内容即可。
代码示例:
"alert alert-block alert-info">Tip: Use blue boxes (alert-info) for tips and notes.
If it’s a note, you don’t have to include the word “Note”.
输出结果:

代码示例:
<div class="alert alert-block alert-warning"><b>Example:b> Yellow Boxes are generally used to include additional examples or mathematical formulas.div>
输出结果:

代码示例:
class="alert alert-block alert-success">Use green box only when necessary like to display links to related content.
输出结果:

代码示例:
class="alert alert-block alert-danger">It is good to avoid red boxes but can be used to alert users to not delete some important part of code etc.
输出结果:

7. 输出一个执行单元中的所有结果
下面来看一下Jupyter Notebook格中包含的几行代码:
In[1]: 10+5 11+6Out[1]: 17
通常一个执行单元只输出最后一行的结果,而对于其他输出我们需要添加print()函数。好吧,事实证明我们可以通过在Jupyter Notebook开头添加以下代码来输出每一行的结果:
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all"
现在所有结果可以被一一输出:
In[1]: 10+5 11+6 12+7Out[1]: 15Out[1]: 17Out[1]: 19
如果要恢复成初始设定:
InteractiveShell.ast_node_interactivity = "last_expr"
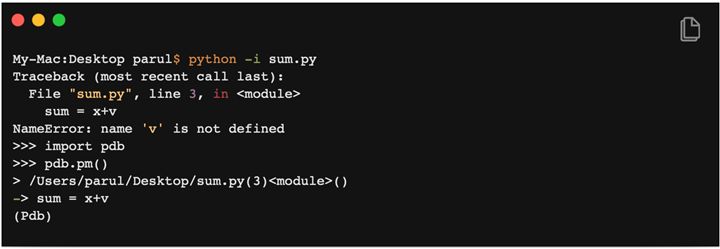
8. 使用‘i’选项运行Python脚本文件
在命令行中运行python脚本的典型方法是:python hello.py。但是,如果在运行相同的脚本文件时额外添加一个 -i,例如python -i hello.py,这会带来更多好处。我们来看看是怎么回事:
首先,一旦程序结束,python不会退出编译器。因此,我们可以检查变量的值和程序中定义的函数的正确性。
其次,
我们可以轻松地调用python调试器,因为我们仍然在编译器中:
这将把我们带到代码发生异常的位置,然后我们可以去处理代码。
源代码链接:
http://www.bnikolic.co.uk/blog/python-running-cline.html
9. 自动添加代码注释
Ctrl / Cmd + / 命令将自动注释执行单元中的选定行。再次点击组合将取消注释相同的代码行。
10. 删除容易恢复难
你有没有不小心误删过Jupyter Notebook中的执行单元呢?如果有,这里有一个可以撤消该删除操作的快捷方式。
总结
在上文中,我列出了在自己在使用Python和Jupyter Notebook时所收集的重要技巧。我相信它们能帮助到你并让你学以致用。到那时我们就可以快乐地写代码啦!
原文标题:
10 Simple hacks to speed upyour Data Analysis in Python
原文链接:
https://towardsdatascience.com/10-simple-hacks-to-speed-up-your-data-analysis-in-python-ec18c6396e6b
吴慧聪,加拿大戴尔豪斯大学计算机和统计双专业本科毕业生,主攻数据科学。准备继续攻读数据分析(人工智能方向)的研究生。对数字极其敏感,善于做各类的数据模型以及分析,希望在数据科学的路上越走越远,也乐于认识更多志同道合的朋友。
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织









