不会写一手漂亮代码的数据科学家不是好工程师。将面向对象编程中那些简单的概念(如函数化和类继承),应用到深度学习原型代码中,可以获得巨大的收益。
本文的目标读者是像我这样没有软件工程师背景的数据科学家和机器学习(ML)从业者,而非经验丰富的软件工程师。
由于 Python 语言对 ML 和数据科学社区来说实在是太棒了,我们通常在工作中使用 Python。它在现代的数据驱动分析和人工智能(AI)应用领域中一路高歌猛进,成为增长最快的主要语言。
然而,Python 同样被用于简单的脚本开发,比如办公自动化、假设检验、创建用于进行头脑风暴的交互式图表,控制实验仪器等等。
但事实是,用 Python 开发软件和用 Python 写脚本并非完全相同——至少在数据科学领域中是如此。
脚本(主要)是写给自己用的代码,而软件则是和队友们一起写给别人用的代码集合。
不得不承认的是,大多数没有软件工程师背景的数据科学家在编写 Python 程序实现 AI/ML 模型或者做统计分析时,往往是写代码给自己用。他们只想快速地直达隐藏在数据里的模式,而没有深入考虑普通用户的需求。
他们写代码来绘制出信息丰富的、精美的图表,但却不会专门创建一个相关的函数,便于以后复用。
他们会导入很多标准库中的方法和类,但是却不会通过继承和添加新的方法来创建自己的子类,以此来扩展类的功能。
函数、继承、方法、类——这些都是鲁棒的面向对象编程(OOP)的核心思想,但是如果你只是想用 Jupyter notebook 来做数据分析和绘图,那么这些概念也不是非用不可。
你可以避免使用 OOP 的那些法则带来的最初的痛苦,然而你总会付出代价的,那就是代码无法复用也无法扩展。
简而言之,你的代码除了你自己以外谁都用不了,到最后你自己也会忘了当初写这段代码的逻辑。但可读性(和由此带来的可重用性)至关重要,这是对你所产出代码的真实考验,不是针对自己,而是面向他人。
但最重要的是,为了降低那些年轻而充满干劲的学习者的负担,网络上数百门有关数据科学和 AI/ML 的在线课程或慕课(MOOC)也都没有强调这方面的编码问题。他们是来学习炫酷的算法和神经网络优化的,而非 Python 中的 OOP。因此,编码方面的问题仍然被忽视。
那么,你能为此做些什么?
简单运用 OOP 的原理就可以大幅改善你的深度学习(DL)代码
我有生以来从未做过软件工程师,因此,当我开始探索 ML 和数据科学时,我草草地写了一大堆的不可重用的代码。
但我逐渐开始尝试优化代码,通过简单地增强代码风格来使代码对于其他人更加有用。
而且,我还发现在有关数据科学的代码中开始应用 OOP 原则并不难。
只要你站在别人的立场上去思考他人会怎样建设性地接受并采用你的代码,即使你从未上过软件工程课程,有些想法也会自然而然地出现在你的脑海中。
-
当你在做数据分析时,如果某一个代码块(完全相同或者略有不同地)出现了不止一次,你能否为其创建一个函数进行封装?
当你创建了这个函数,应该向其传递哪些参数?有哪些参数可以是可选参数?参数的默认值应该是多少?
如果在当前情况下无法确定需要传递多少参数,你使用 Python 中提供的 *args 和 *kwargs 了吗?
你有没有为这个函数写一个「docstring」注释,来说明函数实现的功能、需要的参数以及使用示例等信息?
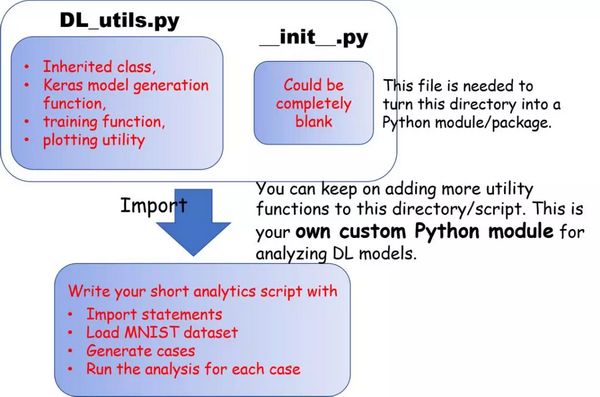
当你已经写了大量此类实用函数后,你是继续在同一个 notebook 上工作,还是新开一个 notebook,然后通过调用「from my_utility_script import func1, func2, func3」导入函数?(前提是你已经根据之前 Jupyter notebook 的代码创建了一个简单的 Python 脚本文件「my_utility_script」。)
你有没有把「my_utility_script」脚本放进一个文件夹,然后在该文件夹下创建一个「__init__.py」文件(哪怕是空文件),以此来创建一个像 NumPy 或者 Pandas 一样的可导入的 Python 模块呢?
你有没有想过在使用像 NumPy 或 TensorFlow 那样功能强大的包时,不仅仅是从中导入类和方法,你还可以向其中加入自己的方法来扩展它们的功能?
以上这些到底意味着什么呢?接下来我们通过一个简单的例子来加以说明——基于「fashion MNIST」数据集来实现一个 DL 图像分类问题。
方法
详细代码见我的 Github 代码仓库。欢迎读者将其克隆(fork)到自己的代码仓库中进行使用和扩展。
代码地址:https://github.com/tirthajyoti/Computer_vision/blob/master/Notebooks/OOP_principle_deep_learning.ipynb
代码对于构建优秀软件至关重要,但却并不适合写文章分析。你可以阅读下面的代码来获得启发,而非实际调试或者重构练习。
因此,我只选取一部分代码片段,以此说明我如何编码实现前文中详细介绍的那些原则。
核心 ML 任务和更高阶的业务问题
核心的 ML 任务很简单——为 fashion MNIST 数据集构建一个深度学习分类器,该数据集是对于传统的著名的 MNIST 手写数字数据集的有趣变体。Fashion MNIST 数据集包含 60,000 张像素大小为 28 x 28 的训练图像,图像内容为与时尚相关的物品,比如帽子、鞋子、裤子、T 恤、裙子等等。该数据集还包含 10,000 张测试图像用于验证和测试。

Fashion MNIST 数据集
但是,如果围绕此核心 ML 任务存在更高阶的优化或可视化分析问题,那么模型架构的复杂度会如何影响达到目标准确率所需的最小迭代次数(epoch)呢?
读者应该清楚我们为什么要为这个问题烦恼,因为这与整体业务优化有关。训练神经网络不是一个简单的计算问题。因此,研究达到目标性能指标必须进行的最少的训练工作,以及架构选择对该性能指标的影响,是很有必要的。
在本例中,我们甚至不采用卷积网络,因为一个简单的密集连接的神经网络就可以达到相当高的准确率,并且事实上我们也需要一些次优的性能来说明前文提到的高阶优化问题的要点。
解决方案
那么,我们需要解决两个问题——
为了实现这两个目标,我们将使用以下两个简单的 OOP 原则:
良好实践的代码片段示例
我们将通过展示下面的一些代码片段,来说明如何简单使用 OOP 原则来实现我们的解决方案。为了便于理解,代码中添加了相关的注释。
首先,我们继承一个 Keras 类从而创建了我们的子类,在子类中添加了一个查看训练准确率并根据该值作出反应的方法。

这个简单的回调函数可以动态控制 epoch——当准确率达到指定阈值后训练自动停止。

我们将 Keras 的模型构造代码封装在一个实用函数中,从而使得任意层数架构的模型(只要它们是密集连接的)都可以通过简单的用户接口传递函数参数来生成。

我们甚至可以将编译和训练代码封装在一个实用函数中,从而在更高阶的优化循环中方便地使用超参数。

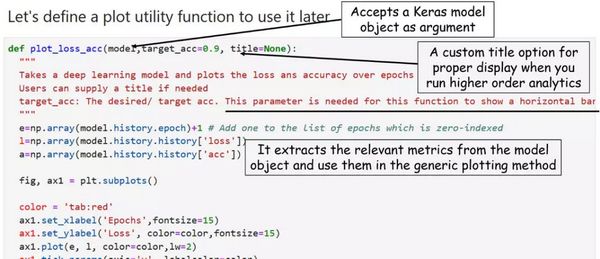
接下来,我们将编写可视化代码,同样地,我们通过函数化实现该功能。通用绘图函数将原始数据作为输入。然而,如果我们有这样一个特殊目的——绘制出训练集上准确率的演化情况并且显示出其与目标准确率的对比,那么我们的绘图函数只需要将深度学习模型作为输入,然后绘制目标图形。
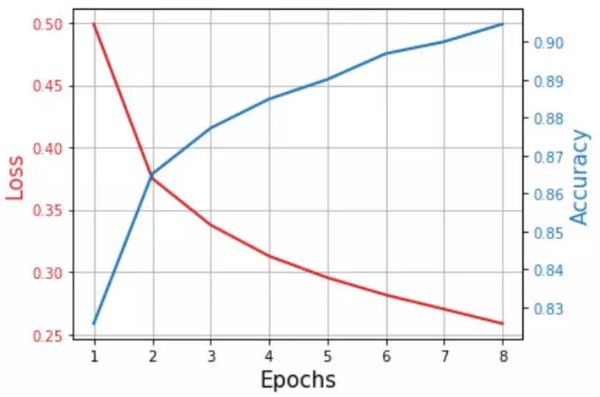
典型的结果如下所示,
最终紧凑简单的分析代码
现在我们可以充分利用之前定义的所有函数和类,将其组合来实现更高阶的任务。
因此,最终的代码将十分紧凑,但它将生成同样有趣的、各种准确率阈值和神经网络架构的损失和准确率随着 epoch 增多而变化的示意图,如前文所示。
这将使得用户可以使用最少的代码来完成性能指标(本例中是准确率)与神经网络架构的选择的可视化分析。这是构建一个优化的机器学习系统的第一步。
我们生成了一些分析案例,
from itertools import product
accuracy_desired = [0.85,0.9,0.95]num_neurons = [16,32,64,128]
cases = list(product(accuracy_desired,num_neurons))
print("So, the cases we are considering are as follows...\n")for i,c in enumerate(cases): print("Accuracy target {}, number of neurons: {}".format(c[0],c[1])) if (i+1)%4==0 and (i+1)!=len(cases): print("-"*50)

最终的分析/优化代码简洁易懂,适用于高级用户,他们不需要了解 Keras 模型构建或回调类的复杂性。
这是 OOP 背后蕴含的核心原则——为完成深度学习任务所做的复杂层次的抽象。
请注意我们将「print_msg = False」传递给类实例的方法。尽管我们在初始检查/调试时确实需要打印出基本的状态,但却需要对优化任务静默地进行分析。如果我们在定义类时未设置该参数,后面就难以停止打印调试信息了。
for c in cases: # Create a mycallback class with the specific accuracy target callbacks = myCallback(c[0], print_msg=False) # Build a model with a specific number of neurons model = build_model(num_layers=1,architecture=[c[1]]) # Compile and train the model passing on the callback class, # choose suitable batch size and a max epoch limit model = compile_train_model(model, x_train,y_train,callbacks=callbacks, batch_size=32,epochs=30) # Construct a suitable title string for displaying the results properly title = "Loss and accuracy over the epochs for\naccuracy threshold \ {} and number of neurons {}".format(c[0],c[1]) # Use the plotting utility function, pass on the accuracy target, # trained model, and the custom title string plot_loss_acc(model,target_acc=c[0],title=title)
我们展示了一些通过执行上述代码自动生成的具有代表性的结果。可以清楚看到,如何通过最少的高阶代码来生成可视化分析,从而判断通过各级性能指标衡量的各种神经架构的相对性能。这使得用户可以根据其性能需求,在不调整较低级别功能的情况下轻松地选择模型。
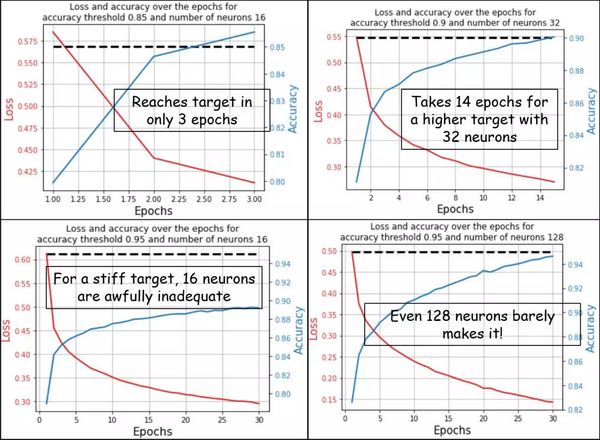
另外,请注意每个图表的自定义标题。这些标题清楚地阐明了目标性能和神经网络的复杂度,从而使分析变得容易。
它是绘图实用函数的一个小细节,但这表明在创建这样的函数时需要仔细设计。如果我们没有为函数设置这样的参数,就不可能为每个图生成自定义标题。这种应用程序接口(API)的精心设计是良好 OOP 的重要组成部分。
最后,将脚本变成简单的 Python 模块
到目前为止,你可能一直在用 Jupyter notebook 工作,但要想在未来任何时候导入这些功能,就需要将其转换成清爽的 Python 模块。
如同「from matplotlib import pyplot」一样,你可以在任何地方导入这些实用函数(Keras 模型的构建、训练和绘图)。
本文展示了一些从 OOP 借鉴而来的简单的良好实践,将其应用于 DL 分析任务。这些内容对于经验丰富的软件开发者来说似乎微不足道,但本文的目标读者是那些可能没有这种背景,但又应该理解在机器学习工作流程中灌输这些良好实践的重要性的数据科学家新人。
冒着重复自己太多次的风险,让我在这里再次总结一下,
只要有机会,就为重复的代码块生成函数。
一定要仔细设计 API 和函数(比如,所需要的最小参数集是怎样的?它们是如何为高级编程任务服务的?)
不要忘了为函数写注释,哪怕只简单写一行说明也行。
如果你为同一对象积累了许多实用函数,那么就该考虑为其定义一个类,并且将这些实用函数作为该类的方法。
只要有机会使用继承完成复杂分析,就可以扩展类的函数。
不要仅仅停留在使用 Jupyter notebooks。请将代码转换成脚本文件,并将它们封装在小模块中。养成模块化工作的习惯,这样任何人都可以轻松地复用和扩展它。
说不定当你攒了足够多的实用的类和子模块时,你就可以在 Python 包管理仓库(PyPi 服务器)上发布实用程序包,然后,你就可以大肆吹嘘自己发布过原始开源软件包了。:-)
原文链接:https://towardsdatascience.com/how-a-simple-mix-of-object-oriented-programming-can-sharpen-your-deep-learning-prototype-19893bd969bd
来源:机器之心










