大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
上一节通过火锅团购数据学习了:
如何使用Pandas的apply()函数;
如何使用Pandas进行分组和聚合操作。
这一节我们继续来学习Pandas这个神器的其他武功:
如何使用Pandas操作时间序列;
如何使用Pandas与Sql结合。
光看商家等级找人均消费最低的还远远达不到“省钱”的目的。还需要什么?团购的具体信息啊!找到等级高消费低的商户的某个中意的团购才能从“一丝狡黠地微笑”变成“一阵狰狞的狂笑”。
这里需要读入另一个文件:coupon_nm.xlsx,这一文件存放团购信息。
1coupon_data = pd.read_excel("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/coupon_nm.xlsx?raw=true")
2
3
4coupon_data = coupon_data[coupon_data['团购评价'] != '暂无评价'][coupon_data['评价人数'] != '暂无评价']
5coupon_data = coupon_data[coupon_data['购买人数'] != 0]
6coupon_data = coupon_data.dropna()
7coupon_data.head(2)
运行结果如图1所示。

图1 团购信息表
由于熊大来西安是今年9月份,和团购到期时间不一定对的上,到时候买了团购又过期了可真是得不偿失,所以,我们得对到期时间做一些处理,先将”到期时间“转换成日期,再按条件过滤即可。
表1 转换时间

例1 转换时间
1print(type(coupon_data['到期时间'].iloc[0]))
2coupon_data['到期时间'] = pd.to_datetime(coupon_data['到期时间'], format='%Y-%m-%d')
3print(type(coupon_data['到期时间'].iloc[0]))
4
5from datetime import datetime
6filter_coupon_data = coupon_data[coupon_data['到期时间'] > datetime.strptime('2018-09-01', '%Y-%m-%d')]
7filter_coupon_data.head()
运行结果如图2。
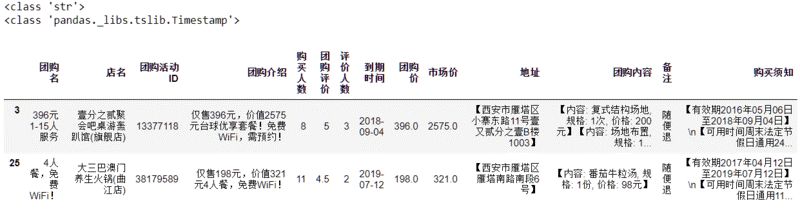
图2 筛选时间
终于删选出来了,熊大赶紧来吧嘻嘻。
虽然团购信息被筛选了出来,但是放在两个表里毕竟不方便看或者建模,因此,还需要把这些信息合并在一张表中。
聪明的小伙伴们肯定第一反应是:要是用SQL语句merge一下就好了!Pandas里有没有类似merge的方法呢?抱歉,没有相似的,只有一模一样的方法。(*^▽^*)贴心的Pandas。
难道就这么直接合并吗?显然不行——一家店可有好几个团购呢,要是直接合并,会出现很多空值。怎么处理呢?为简单起见,我们对其中的某些字段取平均后,再进行合并。
例2 分组聚合
1filter_coupon_data2 = filter_coupon_data.groupby('店名').agg({
2 '团购价': 'mean',
3 '购买人数': 'mean',
4})
5filter_coupon_data2.head(10)
运行结果如图3(部分)。
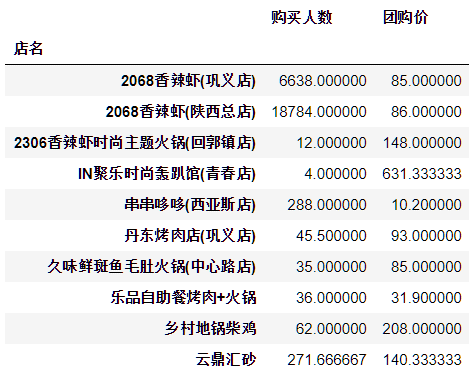
图3
合并使用的函数如下表。
表2 合并

例3 合并
1filter_coupon_data2['店名'] = filter_coupon_data2.index
2
3filter_coupon_data2.index = list(range(len(filter_coupon_data2)))
4filter_coupon_data2.head(10)
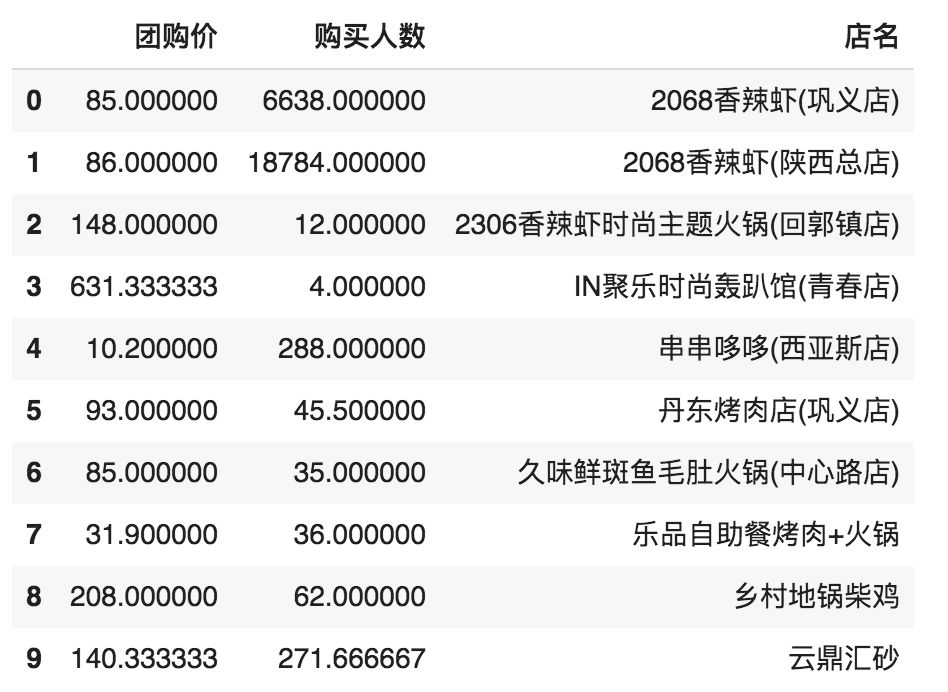
终于要合并的两张表格都有店名的信息了,可以合并了。
1merge_data = pd.merge(left=raw_data2, right=filter_coupon_data2, on='店名', how='inner')
2merge_data['购买人数'] = merge_data['购买人数'].astype(int)
3print(merge_data.shape)
4
5merge_data.head()
运行结果如图4。

图4
咦?怎么合并后的维度只有199行了?因为我们使用了inner的合并方式,只有199家商户有团购活动。注意,由于购买人数一定是整数,所以需要转换成int类型。
最后,可以利用merge_data.to_excel函数将处理完的文件保存成新的文件,注意不要覆盖原文件,以防处理错误导致原文件、新文件都不可用。由于接口和使用方法与读入数据的接口类似,这里不再详细展开接口用法。
好了,今天就先介绍到这里。
作业:载入pandas包,读入coupon_nm的文件。利用本节所学过的知识完成如下内容:首先,把时间修改为美国常用的模式“月-日-年”。其次,把到期时间按照“春-夏-秋-冬”分成四个团购表。最后,合并春夏表写入为“上半年团购到期表”与合并秋冬表写入“下半年团购到期表”。这里“春夏秋冬”自己定义哈哈哈。










