
机器学习调参的思路都异曲同工,首先确定一个参数池,也就是模型参数值的可选范围。从这个池子中挑选出不同的参数组合,对于每个组合都计算其预测精度,最后选取预测精度最高的参数组合。
1.什么是调参?
调参的过程就像是找人生伴侣的过程,首先我们有一个标准,比如身高、体重等,符合这个标准的异性将进入到参数池中。然后我们跟参数池中的每个异性谈恋爱,找到最适合我们的那个作为终极选择。接下来,介绍两种常见的调参方法:网格搜索与随机搜索。
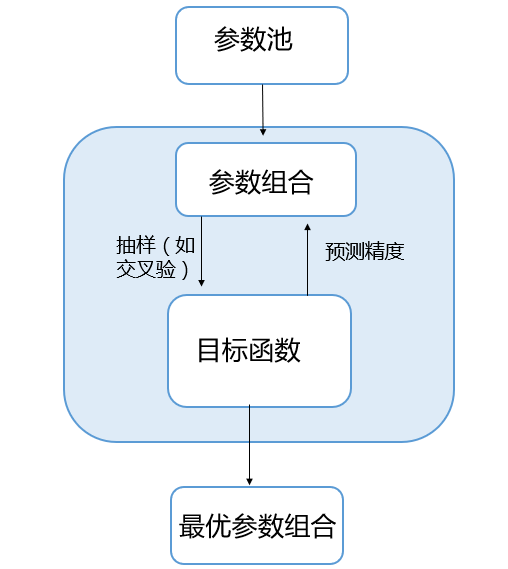
图1 调参流程
网格搜索首先会有一个标准,将符合标准的参数放入参数池中,形成不同的参数组合。而随机搜索则不同,随机搜索没有标准,随机地组合参数。依然以找男友为例,假设参数有3个:身高、体重、年龄。
网格搜索会对这3个参数设定一个范围,比如身高>180厘米,体重小于<140斤,年龄在20~40岁之间,符合这些条件的男性为图2中的左图。但是随机搜索则不同,有些女性觉得如果设定了择偶条件,反而容易错过自己喜欢的,也许适合自己的恰好身高只有179厘米。
这两种不同的搜索方式出来的参数组合是不同的,图2中的左图是网格搜索的参数组合结果,右图为随机搜索的参数组合结果。两者各有优缺点,随机搜索与网格搜索相比,其优点在于能随机地遍历所有参数空间,但是缺点也很明显:不知道随机出来的是什么类型的人。下面分别看看两种搜索方式的实现。
(1)网格搜索

图2 网络搜索和随机搜索
首先来看在caret包中如何轻轻松松实现网格搜索。
• 第一步:设置随机种子,保证实验的可重复性;
• 第二步:利用traincontrol()函数设置模型训练时用到的参数。其中method表示重抽样方法。此处,"cv"表示交叉验证,number表示几折交叉验证,本例中是10折交叉验证。10折交叉验证表示,首先将样本分为10个组,每次训练的时候抽取其中9组作为训练集,剩下的1组作为测试集。classProbs参数表示是否计算类别概率,如果评价指标为AUC,那么这里一定要设置为TRUE。由于因变量为两水平变量,所以summaryFunction这里设置为twoClassSummary。
• 第三步:设置网格搜索的参数池,也就是设定参数的选择范围。这里以机器学习中的gbm(Gradient boosting machine)方法为例,所以有4个超参数需要设定,分别为迭代次数(n.trees),树的复杂度(interaction.depth),学习率(shrinkage),训练样本的最小数目(n.minobsinnode)。这里设定了60组参数组合。

• 第四步:利用train()函数来进行模型训练及得到最优参数组合。该函数会遍历第三步得到的所有参数组合,并得到使评价指标最大的参数组合作为输出。method表示使用的模型,本例使用机器学习中的gbm(Gradient boosting machine)模型,使用的评价指标为ROC曲线面积(即AUC值)。


• 第五步:模型会自动确定ROC曲线面积最大(即AUC值最高)的参数组合,也就是图3中最高的点对应的参数组合,对应的AUC值为90.14%。

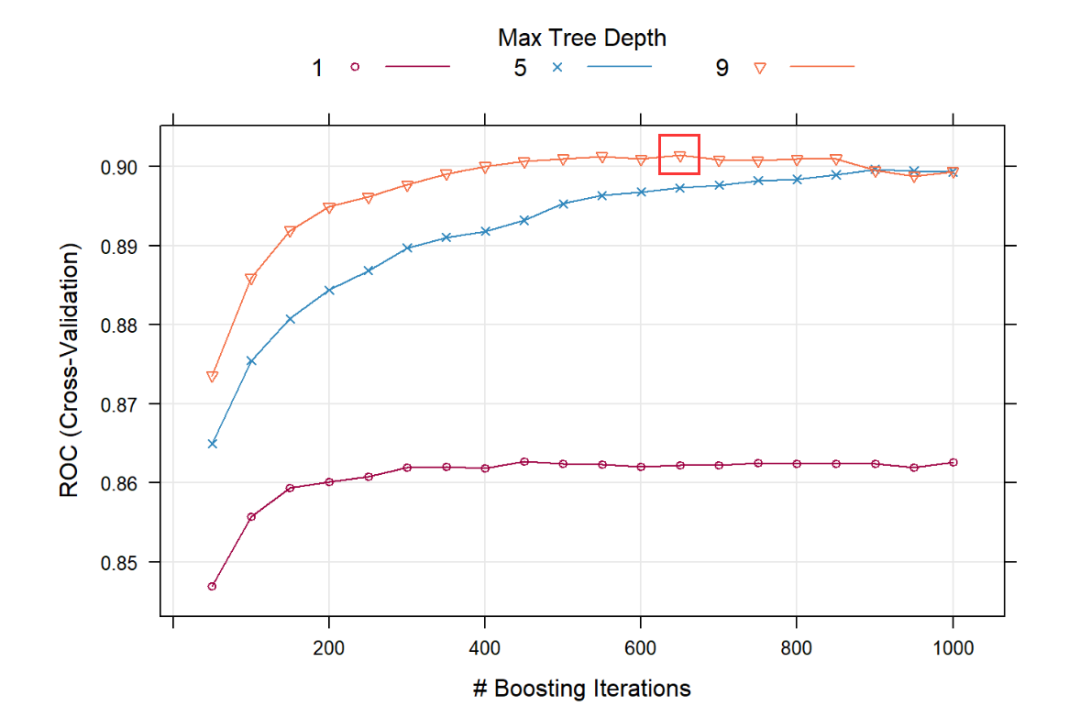
图3 AUC值与迭代次数的折线图
(2)随机搜索
随机搜索与网格搜索相比,参数的选择没有固定的范围,最终的结果可能好也可能坏。它的实现步骤如下:
• 第一步:设定随机种子。
• 第二步:利用trainControl()函数设定模型训练的参数,但是多了一项:search=”random”。

• 第三步:超参数在随机搜索中不受约束,没有条条框框的限制。所以无须设置tuneGrid参数,只需要设置参数tuneLength(随机搜索多少组)。

• 第四步:最优的参数组合如下所示。可以看出,与网格搜索的结果大有不同,对应的AUC值为90.29% ,与网格搜索相比略有提高。

确定最优参数之后,模型如何进行预测呢?使用predict()函数,只要输入模型及测试集,就可以预测了。然后利用confusionMatrix()函数输入真实的Y与预测的Y就可以得到混淆矩阵(Confusion Matrix)。
网格搜索的参数与随机搜索的参数的预测结果有什么区别呢?下面的操作结果可以明显看出两者的区别。
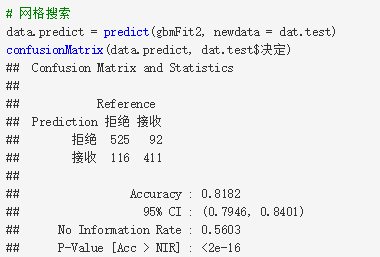

从以上结果看,随机搜索的结果比网格搜索的预测结果更好,这只能说明很幸运,随机地把最好的结果找出来了。
请扫描以下二维码/点击链接购买
《R语言:从数据思维到数据实战》


https://detail.tmall.com/item.htm?spm=a220z.1000880.0.0.0A6pvS&id=581845865737









