
大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
本部分将学习利用sklearn的完成机器学习的基本流程:
● 数据准备
● 模型选择
● 模型训练
在开始学习scikit-learn之前,咱们首先来理解下什么是机器学习。如下图所示,

很明显,是只猫的图片。但是,计算机可不知道这是什么玩意儿!在计算机中,图像也只是二进制文件而已。要让计算机能“分辨”出来这是只猫,我们首先得证明这只猫是只猫,而不是狗!所以,首要问题是如何描述猫的特征。猫常见的特征有:圆脸、两只尖耳朵,几根胡须,肥肚子、一根长尾巴。假设这些特征就已经能明显区分猫和狗了,也就是五个特征维度:脸的形状(圆脸还是长脸)、耳朵的形状(尖耳朵还是圆耳朵)、是否有胡须、肥胖程度、尾巴长度(长还是短),再把这些特征维度转换成计算机能理解的语言,例如得到下面这些这张特征表:
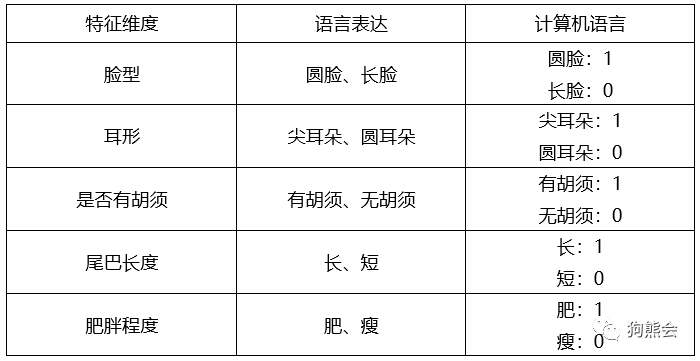
这里规定:圆脸、有胡须、长尾巴、肥胖的动物为猫(尖耳朵或者圆耳朵皆可),特征向量为
[1 0 1 1 1]以及[1 1 1 1 1];长脸、尖耳朵、无胡须、短尾巴、瘦的动物为狗,特征向量为[0 1 0 0 0]。
最终,把得到的特征向量映射到某种函数f输出结果(判断结果是猫的为1,是狗的为0)。即:
f() = “猫” 或者 "狗"。
以上流程可以总结为:
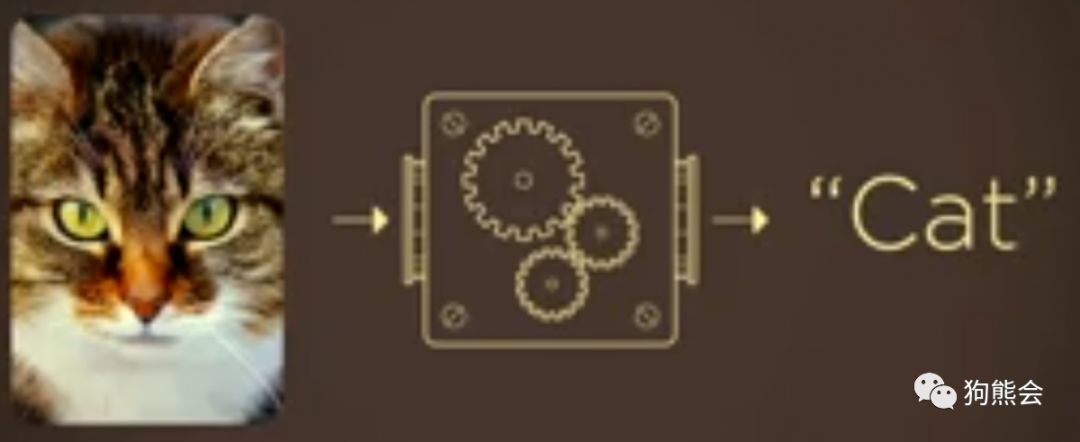
第一个箭头代表特征向量的提取,中间的盒子代表某种函数映射,第二个箭头代表结果判断。
一旦找到了这个最优函数f,再遇到一张图片(外样本)就可以用这个函数f判断是猫还是狗了。
机器学习就是寻找这个最优函数f的过程。
注意:现在本章对于机器学习的描述都集中在了有监督机器学习上,故我们这里混淆了机器学习的部分概念,具体的分类大家可以仔细查找。这样做是为了本章的方便叙述。
本着吃货的本性,我们从“吃”的角度再来深入理解下什么是机器学习。
政委虽然远在西安,但是特别喜欢老北京涮羊肉,一到冬天就停不下来。你要问他推荐一家店,必然推荐市中心那家。"市中心那家羊肉入口即化,食材新鲜、芝麻酱特别好吃、价格厚道、干净卫生...."。每开一家羊肉店,他准能告诉你这家店行不行。
他无数次的吃货经验得出,一家店是否值得经常光顾,主要取决于以下几点:主打菜是否有特色(羊肉味道)、食材是否新鲜、调料是否有特色(芝麻酱)、价格是否划算、店内环境。转换成计算机能理解的语言,也就是、
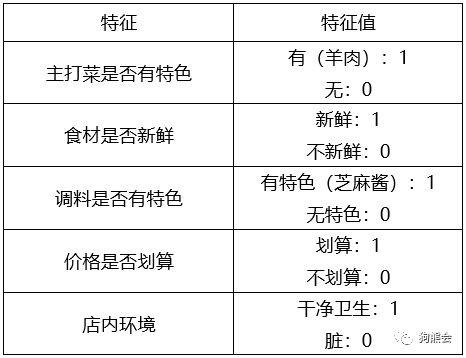
最终,特征向量为[1 1 1 1 1]的店才值得经常光顾;其他特征向量的店则视情况而定。
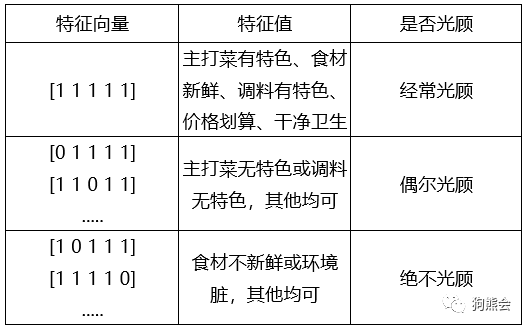
上表简单列举了5种特征向量的情况,对应光顾频率。但是,如果要穷举所有情况,就要列举32次,即使对于资深吃货来说,为吃个饭这样也未免太麻烦。此时,用某个函数f把所有特征向量映射到光顾程度上,这样岂不美哉!也即:
f( 吃过所有店的特征向量 ) = 光顾程度(1→0递减,代表经常光顾和绝不光顾)
通过这个函数映射,所有店的情况都考虑进去了,我们就能据此判断一家新店是否值得经常光顾了。
总结:作为资深吃货,经常光顾各种店,每次光顾可视为一条数据(x),每条数据包含一家店的各种特征(如食材是否新鲜),得到特征向量,以及对应是否会再光顾(y)。通过多次光顾不同店铺(多个x),找到最佳的函数映射(f),据此判断一家新店是否值得经常光顾。
翻译成机器学习的语言就是:根据大量有数据标注(y,是否值得光顾)的特征向量(店的特征),寻找最佳函数,根据验证集的结果选择最佳模型,最终在测试集中测试模型。
明白了什么是机器学习后,我们用火锅数据的例子来完成整个机器学习的过程。
注意:本章不会具体讲解每个机器学习算法的具体函数与使用方法。当大家理解了使用scikit-learn模块的流程后,任何的这个模块中的标准的机器学习算法对应的函数都可以被调用函数使用。具体做法,当然是参考帮助文档。
由于每个吃货对“好吃”的定义不同,以及对“是否经常光顾”的要求不同,我们接下来要生成的数据集的规则如下:
1. 行向量代表一家店的5个特征维度,列向量代表商家的特征维度。
2. 一家店只有上述5个特征,每个特征只有1或者0两种选择。
3. 5个特征中,食材新鲜和店内环境为1,且五项合计总分必须大于等于4分才会再次光顾。
生成的数据集见左下角“阅读原文”。
生成的数据如下图:
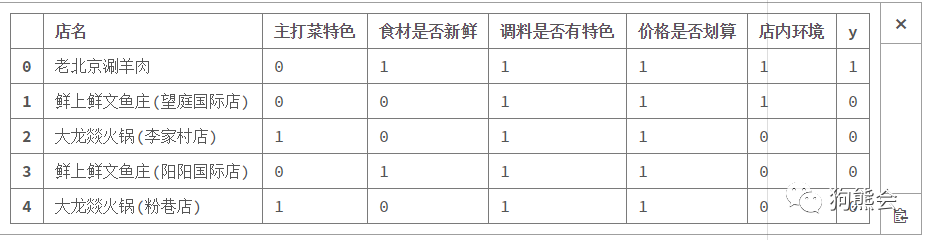
因此,主打菜特色等5种特征可以看做是x,是否会光顾是目标y。通过上述的过程就准备好了需要的数据集。
模型选择不是一成不变的,本质是根据任务选择模型。由于我们是从已知(吃货经验)推未知(新店是否值得光顾),所以这是二分类问题(是否光顾)。下面将会使用决策树模型讲解机器学习的过程。如果读者不了解还有哪些可供选择的模型,可以到scikit-learn的官网(https://scikit-learn.org/stable/)查看。
这个例子可以从以下角度理解决策树模型:
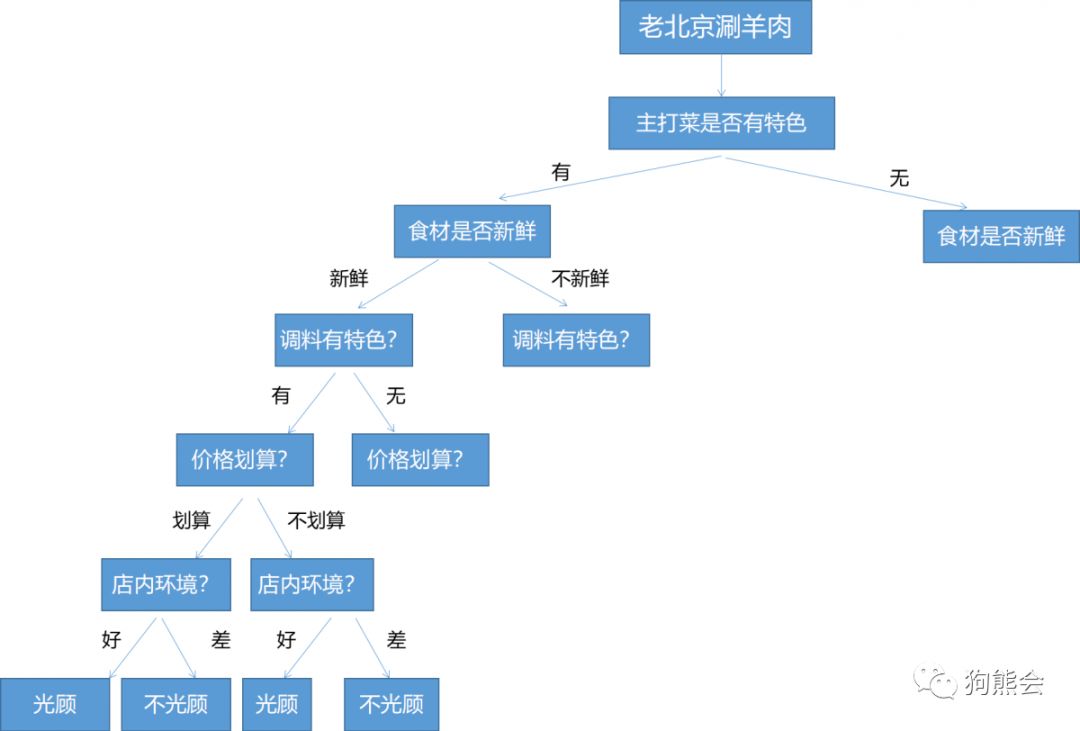
囿于空间有限,这里只画出部分决策过程(完整决策过程后面会详细阐述)。以“老北京涮羊肉”这家店为例,每个节点都是一个特征维度:先主打菜有无特色?再判断食材是否新鲜?食材不新鲜的节点之后的特征无论判断如何,最终结果都为“不光顾”;调料是否有特色?价格是否划算?店内环境如何?这些决策问题上的任何差评都最终导致”不光顾“。
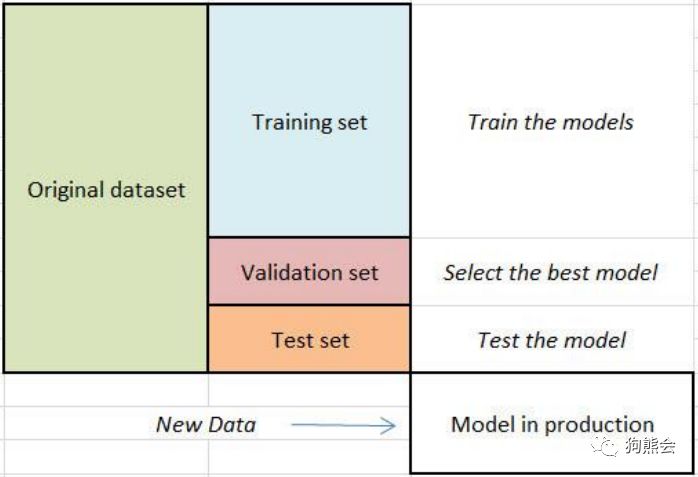
1. 切分训练集、验证集、测试集
准备好的数据集在机器学习中的使用过程如下图所示:首先把原始数据集分成三份:训练集,验证集与测试集。然后,在训练集上训练模型,在验证集上选择最优模型(一般会选择确定模型的某些参数),在测试集上测试得到的模型的性能。
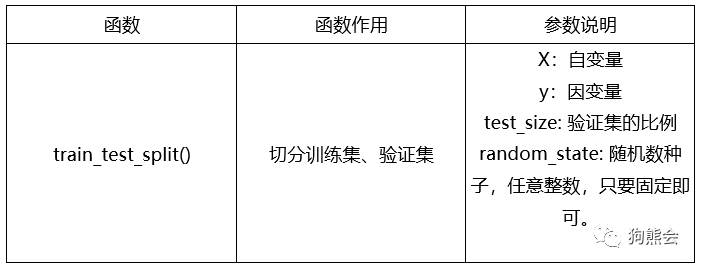
常用函数说明
代码(见chapter6/scripts/learn.py)如下:
from sklearn import tree
from sklearn.model_selection import train_test_split
data = pd.read_excel("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/shops_nm_cleaned.xlsx?raw=true", encoding='utf8')
data.head()
X_train, X_val, y_train, y_val = train_test_split(data.iloc[:, 1:-1], data.iloc[:, -1], test_size=0.3, random_state=0) #划分训练集与验证集
X_val, X_test, y_val, y_test = train_test_split(X_val, y_val, test_size=0.3, random_state=0) #划分验证集与测试集
print('训练集的自变量维度: {}, 因变量维度: {}\n'.format(X_train.shape, y_train.shape))
print('验证集的自变量维度: {}, 因变量维度: {}\n'.format(X_val.shape, y_val.shape))
print('测试集的自变量维度: {}, 因变量维度: {}\n'.format(X_test.shape, y_test.shape))
运行结果如下图:

在上面代码中,我们利用train_test_split()函数把所有数据先切分成训练集和验证集,再从验证集中切分测试集,所以调用了两次train_test_split()。test_size均为0.3,即最终训练集、验证集和测试集的比例是:0.7:0.2:0.1,random_state参数只要设置为固定值即可,这是因为这个函数是“随机”切分,但目前计算机生成的随机数都只是伪随机数,生成的不同随机数对切分结果有轻微影响,所以需要指定随机数种子,只要每次切分的随机种子一样,那么结果就可以忽略这个影响。最终print出结果检查维度是否正确即可。
2. 训练模型
常用函数说明
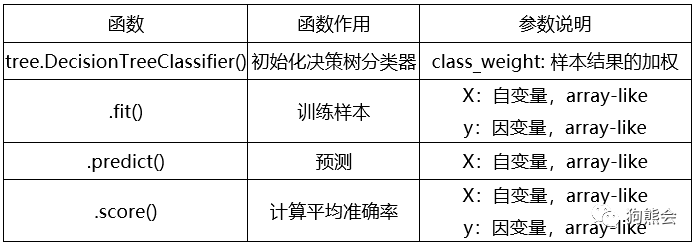
代码如下:
# 初始化决策树分类器
clf = tree.DecisionTreeClassifier()
# 训练样本
clf = clf.fit(X_train, y_train)
# 在验证集上计算平均准确率
clf.score(X_val, y_val)
# 预测样本
clf.predict(X_val)
最终结果是1.0,即完全预测准确。scikit-learn的使用非常简单,无论是什么模型,调用函数也是4步走:
1.模型初始化。针对模型各种参数的调整都是在这一步。
2.调用fit()函数训练样本。每次调整完后都需要重新训练样本。
3.调用score()在验证集或者测试集上计算平均准确率。
4.输出验证集或测试集的预测结果。
这一步不是必须的,但是有时往往会由于各种原因而导致模型训练出现过拟合或者欠拟合,所以输出结果以查看模型结果是否可信。
以上步骤即是调用完整模型需要的接口,scikit-learn为每个模型都继承了几乎一样的接口函数,使用起来非常方便。










